Automatic Text Recognition (ATR) - Text Recognition and Post-ATR Correction
This resource recaps Automatic Text Recognition (ATR) process and concentrates on how to correct output from ATR pipelines. The last part is dedicated to open-source tools available for post-ATR correction.
This is the English version of this training module. The video is available with English, French and German subtitles.
Si vous souhaitez accéder à la version française du module, rendez-vous ici.
Die deutsche Version der u.s. Lerneinheit ist hier verfügbar.
Learning outcomes
After completing this resource, learners will be able to:
- have a comprehensive view of the ATR pipeline
- assess their post-ATR correction needs
- define the post-ATR correction method they want to use
- choose the relevant tool to that end.
Automatic Text Recognition (ATR) in a nutshell
In the beginning there was nothing. And humans said, ‘Let there be automatic text recognition’. And so humankind created the ability to convert analog text, be it handwritten or printed, into digital copies. Automatic text recognition describes the convergent usage of optical character recognition (OCR) and handwritten text recognition (HTR). However, this important development was not achieved as fast as lightning.
OCR is aimed at treating printed media, such as books. This technology has only improved over time, and systems nowadays can have an accuracy of 99% in recognising text from printed documents. HTR, as the name suggests, is used for handwritten documents, such as letters. Both OCR and HTR enable the digitisation and preservation of historical documents, improve their accessibility, and allow for efficient data extraction. Human handwriting poses a challenge even for modern technology, as manuscripts encompass a near-endless range of fonts and styles. It is out of range for traditional approaches of pattern matching, which is the crux of OCR.
Evolving technologies have allowed for text recognition systems to now do both HTR and OCR simultaneously. Modern models can recognise printed as well as handwritten text and process segments in lines or entire paragraphs. Today, such systems are built into smartphones, allowing us to scan text from images. These technologies are especially appealing to historians, librarians, archival staff, and scholars in general who want to convert, analyse, store or maintain their documents in a novel way, adopting global digital trends.
Three important projects using ATR

Three ATR projects: Gallica, ABO and Project Gutenberg
To begin with, let us explore three significant ATR projects that have made a lasting impact. These projects are Gallica, Austrian Books Online (ABO), and Project Gutenberg. Gallica is the digital counterpart to the French national library (Bibliothèque nationale de France) founded in 1997. Austrian Books Online (ABO) is an ongoing mass-digitisation project started by the Austrian National Library, in which the Library’s historical book holdings are made available through a public-private partnership with Google. Project Gutenberg is a digital library that offers a diverse range of cultural texts in the form of eBooks. The archive includes more than 50,000 items, for example, Faust by Johann Wolfgang von Goethe or Germinal by Émile Zola, i.e. literature in the public domain, dating mostly from the 19th century and prior, depending on the copyright law of the country of origin of the work.
Text recognition
What is text recognition, and how does it work? Depending on whether we look at OCR or HTR systems, the baseline functionalities of these systems differ. To recap, text recognition is the procedure of converting scanned images of text into a machine-readable text format. This can be done manually in a ‘double keying’ process, or it can be carried (semi-)automatically with the help of ATR systems and trained models.
Such models require the input of images of high quality in order to do so. A corresponding data pipeline for ATR, i.e. the classical workflow to follow when processing data, would include the preprocessing of images, the segmentation phase, the actual text recognition process, and a post-correction step. Modern models recognise segmented lines with the help of deep learning algorithms, which allows them to build a textual representation of the image input. These algorithms learn visual characteristics from such input. Depending on the project’s goals and background, you can use either existing models or train a new model that will fit your specific case. The transcription process–be it through ATR or manual transcription–will produce machine-readable text as the output.
Ground truth and model training
Various training data and models can already be found on platforms such as HTR-United, Zenodo, and GitHub. Therefore, before jumping to training a new model, it is better to ensure that it is, in fact, really necessary. By exploring existing training data you may be able to skip time-consuming steps involving the production of ground truth and the training of models.

Some platforms for ground truth and models: HTR-United, GitHub and Zenodo
Before delving into ATR techniques, it is essential to define some keywords. First, ground truth refers to information that is known to be real or true; it is the ideal, expected result. In automatic transcription, ground truth is the exact transcription of a set of texts. It renders flawlessly the content of the images it is associated with and is then used for training. A model is a file that has been trained to recognise certain types of patterns. A ground truth becomes a model through model training, which, when done via machine learning, characterizes the process by which a machine learning (ML) algorithm is fed with sufficient training data to learn from.
Model training is a task that consists of several steps. First, it requires an input, i.e. the data from which the software will learn to produce an output. For text recognition, this input includes, a set of images and their corresponding transcription (the ground truth). Once it is obtained, the input will be fed into the model training software, a topic we will delve into later. During the model training, the software will train on the data and learn from it, develop some patterns’ recognition, test and validate the results of this training, and then repeat until it comes up with a satisfactory model, which is what constitutes the output.
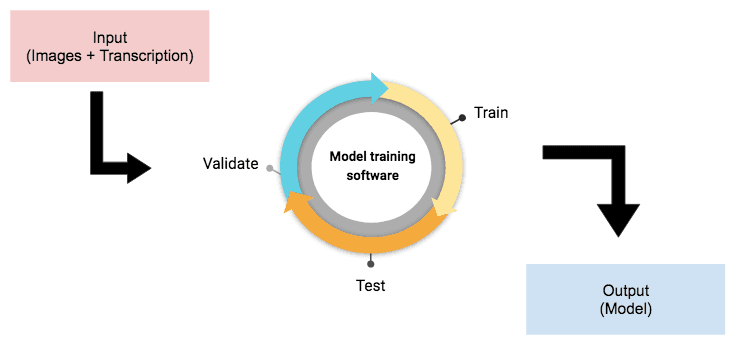
Schema of a model training
As ground truth is used for model training, it is imperative that the proposed transcription matches the images exactly so that the model is not confused during the learning process. In order to do so, it is necessary to produce ground truths entirely by hand or with a predicted transcription, followed by a meticulous manual correction. It is also essential to produce a sufficient quantity of ground truth, otherwise the model will have trouble learning and produce an inaccurate transcription. There is no minimum number of lines or pages required for model training as it depends on various parameters, such as the quality of the images, the intricacy of the writing, and the structure of the documents.
Importantly, producing ground truth and training a model can be done gradually–it is always possible to add new ground truths until the model is sufficiently accurate. Finally, when producing ground truth, it is crucial to remain consistent in the choices made for the transcription, such as specific characters or glyphs. Documenting the choice made and then adhering to it throughout the entirety of text recognition is a good way to ensure that the model will not be confused and that the ground truth can be reused and understood more easily by the rest of the DH community.
Software for text recognition
If the process and methods for text recognition are now certainly established, it should be noted we are not working in a field where one software dominates. Automatic text recognition can be used for various types of documents and languages and consequently, several ATR software have been created, each with their own capabilities. Therefore, recommending a single software to carry out text recognition would not be judicious or pragmatic. Instead, we are going to introduce some elements to consider in order to choose the most fitting software. It is essential to think carefully while choosing an ATR software because changing software mid-work is not always possible and even when it is, it can lead to issues.
Here are some elements to consider with your data and in ATR software parameters in order to make the best choice. Firstly, it is important to examine the type of documents that constitutes your data: is it a printed document, handwritten document, or does it include a bit of both? Knowing this can already eliminate many of the options because OCR software does not generally work on handwritten documents. Moreover, if you are working with printed documents in a pretty standard font, creating ground truth in an HTR software as no fitting model exists in it, would just be a waste of time, whereas OCR software usually have models already ready for all type of fonts and languages.
If several software programs seem adequate, it would be wise to look at the models available, or if none exist, at the ground truth to, once again, avoid having to do more work than necessary. In addition to the type of documents, the other essential element to verify before choosing an ATR software is determining the scripts it can handle, i.e., the writing systems it can work on. For example, selecting an ATR software only made for Latin scripts while working with Arabic texts would be inefficient and useless.
In terms of image acquisition, you can retrieve your images in various kinds of formats, such as TIFF, JPG, PDF, on your local machine or even already on a IIIF server. As those images will be inputted in the ATR software, it is necessary to verify beforehand that the format you have is compatible with the software selected.
Lastly, in the case of several choices when picking the most fitting ATR software, the presence of graphical user interface could be worth considering. Even though it would usually have no impact on text recognition, an interface could be advantageous as per your own affinity with technical tools.
Post-ATR correction
The post-ATR correction is the step that proceeds the prediction made by the model, which has been applied to a corpus of images. The goal of this step is to fix the mistakes of the prediction in order for it to match perfectly with the images transcribed, making it a ground truth. Software programs, model training, and the quantity of resources in ATR have greatly improved in the last few years, enabling the production of more accurate and efficient recognition models. However, the probability of an automatic prediction producing a flawless result is rarely 100% and in almost every case it will be necessary to correct the prediction after applying the model.

Example of a post-ATR correction.
Errors in prediction can be the result of many factors related to the scanned image, the model, or segmentation, such as noisy backgrounds, bad paper quality, illegibility of a text, an unfit model, or wrong masks and polygons in the segmentation. Faced with such situations, if you require a ground truth, it will be necessary to do a post-ATR correction in order to obtain an output matching perfectly with its associated image.
There are two possible ways to do post-ATR correction: semi-automatic correction and full manual correction. In both cases, if a perfect transcription is desired, manual correction must be performed. Choosing to do one or the other will really depend on the amount of errors in the prediction, as semi-automatic correction can be time-saving when errors happen over every few lines but will turn into a waste of time if there are only occasional errors. Moreover, techniques and tools for semi-automatic correction vary, and its utility depends on the user’s affinity with digital tools. Therefore, we advise using semi-automatic correction only if you estimate that there will be a true, significant opportunity to save time. If not, then we advise doing a full manual correction, i.e. checking the transcription for errors and doing the modification by hand.
Tools for semi-automatic correction
Python scripts and regex
- Script: https://github.com/DiScholEd/pipeline-digital-scholarly-editions/tree/master/post_ocr_correction/scripts
- Documentation: https://github.com/DiScholEd/pipeline-digital-scholarly-editions/blob/master/post_ocr_correction/post-ocr_correction_for_text_files.md
Python scripts, regex, and context
- Scripts: https://github.com/sbiay/CdS-edition/blob/main/htr/py/spellcheckTexts.py and https://github.com/sbiay/CdS-edition/blob/main/htr/py/textCorrection.py
- Documentation: https://github.com/sbiay/CdS-edition/blob/main/htr/Corriger_une_prediction.ipynb
Neural approach to correction
- Project: https://github.com/GarfieldLyu/OCR_POST_DE
- Article: Neural OCR Post-Hoc Correction of Historical Corpora
Conclusion
Post-ATR correction is a key element of the Automatic Text Recognition pipeline. Decisions on whether to automatise it or part of it are integral to the exploration and research process. Semi-automatic methods are usually a balanced choice, for which a series of open source tools are available.
The “Automatic Text Recognition Made Easy” curriculum
This module is part of a wider ‘Automatic Text Recognition Made Easy’ Curriculum. You may also wish to visit the next module in this curriculum, Automatic Text Recognition (ATR) - End Formats and Reusability.