Introduction to the European Collaborative Cloud for Cultural Heritage
The Cultural Heritage Cloud (ECCCH) is a major European initiative designed to provide heritage professionals and researchers with access to data and advanced digital tools. The goal of this course is to build learners’ foundational understanding of the key concepts and technologies necessary to engage with the cloud, demonstrate some of its practical tools and applications, and inspire their further exploration of digital transformation in the heritage and research domains.
Learning Objectives
Upon completion of this course, learners will be able to:
- understand key concepts such as collaborative cloud, digital commons, digital twins, and vertical applications
- grasp the relevance of the Cloud for cultural heritage and research work
- identify the main players, applications, and tools within the Cloud
- recognize pathways for continued learning and next steps for engaging with the Cloud
Target Audiences:
- Cultural heritage professionals
- Researchers in the arts and humanities
- Students in the arts and humanities
- ECHOES Cascading Grants applicants and winners
- Policymakers
Intended Impact
This course lowers the entry barrier to the emerging European Collaborative Cultural Heritage Cloud by providing a clear, accessible introduction to its concepts, services, and participation pathways. It addresses the practical need for non-technical orientation to a complex and evolving infrastructure, while contributing to the strategic goal of building capacity across the cultural heritage sector. By preparing users to understand, follow, and eventually engage with the Cloud, it supports broader, more informed participation in a connected, interoperable, and community-driven digital commons.
Requirements
No prior experience with cloud technologies or advanced digital tools is assumed. Basic digital literacy and curiosity about collaborative digital practices in cultural heritage will help users take full advantage of this course.
Unit 1: Understanding the Cultural Heritage Cloud
Most of us already work “in the cloud” every day, often without thinking about it. When you store images in Dropbox, write in a shared document, join a Zoom meeting, stream music online or upload files to your institution’s online repository, you are using so-cloud cloud services. In other words, you are interacting with remote computers through your web browser or an app on your phone: it is those remote computers that are storing data, running software, or processing information on your behalf.
But the everyday clouds most of us use are general-purpose. Services like Google Drive, Dropbox, Microsoft OneDrive, or commercial photo-storage platforms are designed to work for almost everyone: from a neighbourhood café coordinating staff schedules to large architectural firms sharing design files. Their features are intentionally broad and generic.
If you work in a museum, archive, library, or academia, you usually have to adapt these one-size-fits-all tools to your own specialised needs. And this is rarely straightforward. You often face complex questions that these generic platforms were never built to handle:
- How do you manage rights and copyright in digitised collections?
- How do you ensure long-term preservation rather than short-term storage?
- What happens with sensitive materials, community knowledge, or restricted access items?
- How do you support multilingual audiences and culturally diverse interpretations?
- How do you document the provenance, context, and history of an object in a way that makes sense inside a cloud platform designed for office documents?
While the general-purpose cloud services can be helpful, they often leave cultural heritage professionals working around their limitations rather than with tools designed specifically for their needs. A purpose-built cloud like the ECCCH turns this logic around. Instead of asking museums or archives to adapt to generic tools, it starts by asking: what specific tools do cultural heritage professionals actually need? And how can those tools help them simplify their workflows?
What is the ECCCH?
The European Collaborative Cloud for Cultural Heritage is a major European Union initiative to build a specialised digital environment for cultural heritage and heritage-related research.
At its core, the Collaborative Cloud is a shared working space. It is designed to help heritage professionals and researchers work with cultural heritage data across institutional and national boundaries. It provides a digital environment where users can discover, connect, annotate, analyse, and process cultural heritage data from different collections using shared tools and services.
A purpose-built cloud like the ECCCH does not aim to replace every local system, nor does it centralise all heritage data in one place. Instead, it creates a trusted, heritage-specific environment where both individuals and institutions can collaborate using tools designed specifically for cultural heritage workflows rather than generic office work.
Instead of requiring every institution to develop and maintain its own advanced infrastructure, the Cloud makes shared computational services and collaborative tools available across the cultural heritage community. It is also designed to evolve gradually over time, expanding through new datasets, services, tools, and collaborations contributed by different projects and communities.
To keep the text readable, we will alternate between the terms ECCCH, Collaborative Cloud, and simply the Cloud (capitalised) throughout this course. All three refer to the same initiative.
ECCCH: The Origin Story
The idea of a Cultural Heritage Cloud did not appear out of nowhere. It emerged from a recognition of shared challenges across the sector: fragmented data, limited technical capacity in many institutions, and the difficulty of connecting tools, collections, and expertise across borders. These challenges were articulated in a key expert report on a European Collaborative Cloud for Cultural Heritage, which described the Cloud as a shared digital infrastructure for collaboration across the cultural, creative, and technological sectors, and, ultimately, as “a place where everyone meets everyone.” (p10)
In June 2022, the European Commission formally launched the initiative, and set aside a budget of around €110 million from the Horizon Europe programme until 2025, which makes the ECCCH one of the largest European investments ever in cultural heritage.
The main project building this Cloud is ECHOES (European Cloud for Heritage Open Science), which began in 2024 and will run for five years. ECHOES is responsible for laying the foundations of the Collaborative Cloud by:
- developing the core technical infrastructure and producing the first set of cloud-based applications;
- working out the future governance model and legal framework of the Cloud, i.e. determining how the Cloud will be organised, managed, and sustained after the ECHOES project itself ends; and
- running cascading grants, i.e. smaller grants distributed to heritage institutions and partners to bring in data, pilot tools, and new communities to the Cloud.
If you are applying for or have received an ECHOES Cascading Grant, your project is not “just another digital project”. It is meant to become one of the building blocks of this larger European environment.
Why does the ECCCH matter?
Over the past decades, cultural heritage organisations have been digitising different kinds of assets: catalogues and finding aids, images of artworks, objects, and documents, audio and video recordings, and increasingly, 3D scans and complex documentation of buildings, sites, and artefacts. Platforms like Europeana already give access to tens of millions of digital heritage items from thousands of institutions.
At the same time, artificial intelligence (AI) and data‑intensive methods are moving from experimental projects into everyday practice. Handwriting recognition can help transcribe historical documents; automated translation can make texts accessible across languages; image recognition can identify places, people, or artistic styles; while simulations and visualisations can be generated from 3D models.
This creates tremendous potential, but also sharpens three long‑standing problems:
- Fragmentation. Data is scattered across many servers, projects, and platforms. Tools are often one‑off prototypes. Small institutions, in particular, struggle to keep up once a funded project ends.
- Inequality. A large national museum with an IT department and dedicated funding can experiment with AI workflows, virtual exhibitions, and custom-built platforms. A small local museum often cannot, even if its collections are just as important for their communities. This disparity can contribute to growing inequality in the representation, findability and enrichment of heritage assets across Europe.
- Sustainability and ethics. Digitisation alone is not enough. Digital materials must remain accessible, usable, and meaningful over time. They must also be managed in ways that respect legal rights, communities, and sensitive heritage. AI raises additional questions: how is training data selected? Whose knowledge is represented in them? Who benefits from the resulting models? And who is responsible when something goes wrong?
The Cultural Heritage Cloud is designed to address these challenges by:
- reducing fragmentation through shared infrastructure, interoperable services, and tools that institutions can use collaboratively rather than building everything independently;
- reducing inequality by giving smaller institutions access to advanced digital tools, expertise, and training resources that would otherwise be difficult to develop or sustain locally; and
- supporting sustainable and responsible practices through trusted standards, legal and ethical frameworks, and the principles of Open Science, enabling heritage data, tools, and knowledge created with public funding to remain reusable and accessible over time.
Key Actors
ECCCH is deliberately designed as a shared European endeavour. Several groups play key roles in shaping and running the Cloud. Click on each section below to learn more about the different actors involved in building, governing and using the Cloud.
European Commission and EU Programmes
The European Commission sets the overall direction of the Cultural Heritage Cloud and provides funding primarily through programmes such as Horizon Europe. These programmes support both the development of the Cloud’s infrastructure and the tools and services built on top of it.
ECHOES Consortium
The ECHOES consortium is responsible for building the foundations of the Cultural Heritage Cloud. It brings together research institutions, infrastructure providers, and heritage networks, representing a wide range of professional communities, including conservators, archivists, curators, librarians, researchers, and digital heritage specialists, whose expertise and needs are central to the Cloud’s development.
In addition to developing the technical infrastructure, ECHOES is also working on governance, community engagement, and cascading grants that allow new institutions and projects to contribute to the Cloud.
Data spaces
The common European data space for cultural heritage is led by the Europeana Foundation and its partners. It builds on the long‑standing Europeana initiative that already aggregates metadata bout millions of items from European cultural heritage institutions.
In parallel, the European Open Science Cloud (EOSC) provides a broader research data space for sharing and reusing scientific data across disciplines.
Cultural heritage data also has relevance beyond research and memory institutions – for example, in the emerging European tourism data space, where heritage content can be reused to support sustainable tourism, interpretation, and cultural routes.
European Research Infrastructures
Several European research infrastructures participate in ECHOES and play important roles, especially in connecting the Cloud to research communities.
For example, DARIAH‑EU supports digital research in the arts and humanities and runs platforms like DARIAH‑Campus, which hosts training materials, including this course, that help researchers and heritage professionals build the skills they need to use the cloud.
E‑RIHS (European Research Infrastructure for Heritage Science) connects laboratories, facilities, and data for heritage science across Europe. It brings expertise in 3D documentation, scientific analyses of materials, and monitoring of sites and objects, all highly relevant to ECCCH.
CLARIN provides access to language resources and tools for working with text and speech data, using advanced linguistic analysis, corpus tools, and multilingual processing that are directly pertinent to cultural heritage collections.
ARIADNE Research Infrastructure integrates archaeological datasets and services across Europe, improving interoperability and access to archaeological data and supporting cross-border research.
ECHOES Sister Projects
ECHOES is one of a total of twenty-two EU-funded projects collectively building the European Collaborative Cloud for Cultural Heritage. While ECHOES is responsible for developing the core infrastructure, its “sister projects” will each contribute specialist tools and applications that will become part of the shared Collaborative Cloud.
These projects, which will be launched successively through several waves of European Commission funding calls, reflect the Cloud’s gradual and collaborative growth model. Together, they will address a wide range of challenges across domains such as industrial heritage, music, archaeology, palaeontology, and colour science.
You can read more about the first round of funded sister projects here.
ECHOES Cascading Grant Recipients
The ECHOES Cascading Grants Programme offers funding for up to 50 projects to enhance digital engagement, data sharing, and collaboration within the Cultural Heritage Cloud. This program is open to both individual Cultural Heritage Institutions (CHIs) and to consortia led by CHIs.
The grants are distributed through three calls addressing different aspects of the Cloud’s development: the first call focused on data, and will fund 12 projects with €60,000 per project, designed to encourage stakeholders in the Cultural Heritage Community to contribute datasets for use in the ECCCH. The second call focused on engagement and collaboration. It funded 20 projects involving both tangible and intangible heritage, with the goals of increasing awareness of the ECCCH and strengthening skills and capacity-building activities across the sector.
The third and final call, scheduled for January 2027, will encourage stakeholders to contribute both datasets and applications for use in the Cultural Heritage Cloud.
CH Institutions and Communities
Finally, and most importantly, cultural heritage institutions themselves are central actors:
- museums, archives, libraries, and galleries;
- heritage agencies and monument boards;
- community archives, artist‑run initiatives, local historical societies;
- professional networks such as NEMO, ICOMOS, ICOM and others.
They are meant not only to use the Cloud but to co‑design it through consultations, pilot projects, and participation in governance structures. Without their involvement, the Cloud would risk becoming a purely technical exercise. With them, it can become a genuinely shared space that reflects the diversity of European heritage.
Learning Tasks
Throughout this course, you will encounter two different types of learning tasks: exercises and activities.
Exercises are short knowledge checks designed to help you test your understanding of key concepts introduced in the course. These are usually interactive tasks such as multiple-choice questions that provide immediate feedback.
Activities are more open-ended and reflective. They are not graded and typically do not have a single correct answer. Instead, they are designed to encourage critical thinking, discussion, and the application of course concepts to your own professional context. Activities can be completed individually, used for classroom discussion, or adapted for workshops and collaborative learning settings.
Exercise
Take a moment to test your understanding of the material covered so far.
Supplementary reading
The ECCCH ex-ante report provides a more detailed overview of the vision, motivations, and proposed architecture of the Cultural Heritage Cloud for those who would like to explore the topic in more depth.
Unit 2: Key Concepts and Foundations
In Unit 1, we talked about “the cloud” as a working environment in which the tools you use and the data you work with don’t have to live on your own computer. Cloud computing changes how you access resources, how you store and share information, and how you collaborate with your colleagues.
But we have so far only scratched the surface. If you want to understand what the European Collaborative Cloud for Cultural Heritage is trying to accomplish, and, especially, if you want to get involved, you need to look more closely at some of the key concepts that are shaping this initiative. These concepts, such as digital twins, interoperability, data models, may sound technical at first. And we have to be honest about it: they are. But they are closely connected to everyday tasks in cultural heritage work, from digitisation and cataloguing to conservation and research.
Because cultural heritage work involves many different communities, from curators and conservators to researchers and developers, it is important to have a shared way of talking about these concepts. Without a common vocabulary, we risk wasting a lot of energy talking past one another.
In this unit, we will explore a set of key concepts that underpin the ECCCH, and explore how they relate to everyday practices in cultural heritage institutions.
Introducing the ECHOES Glossary
When people from different backgrounds and domains work together, the same word can quietly mean different things. Even relatively common terms such as “metadata” (data about data), “infrastructure” (basic facilities or services), or “workflow” (sequence of steps in a process) can carry distinct assumptions depending on one’s profession or experience. In such cases, a shared glossary can be very helpful: it doesn’t force everyone to think the same way, but it helps everyone communicate more clearly and efficiently.
To help avoid confusion, ECHOES provides a shared glossary of key terms used throughout the project.
The ECHOES Glossary is designed as a practical reference. You can use it whenever you encounter a term you are unsure about, or when you want to understand how a concept is used in the context of the Cultural Heritage Cloud. The terms are based on existing vocabularies in the cultural heritage domain and have been reviewed by domain experts. The glossary is also multilingual and will continue to evolve as new terms are added and refined over time.
You don’t need to memorise any of the definitions that we will share with you in the following sections. We will introduce each of the key terms gradually, through a concrete example that you can follow step by step. The glossary will be there as a reference you can return to whenever you need it, one concept at a time.
A Manuscript in the Cloud: Exploring Foundational Concepts
Imagine you work at a small regional museum. In your storage room, carefully wrapped and rarely displayed, lies a 14th-century illuminated manuscript. As a physical object, it has weight, texture, material properties, and a specific history. Its pigments are still vibrant. Its binding shows signs of centuries of repair. Marginal notes reveal traces of readership across time.
The museum decides to digitise the manuscript. A photographer captures high-resolution images of each folio. A conservator documents the state of the parchment and the pigments. A curator records descriptive metadata: title, approximate date, place of origin, script type. A historian adds notes about provenance. Eventually, a 3D scan is produced to document the binding and its structure.
As a result of these activities, the manuscript begins to exist in two forms: the physical object in museum storage, and an enriched digital representation made up of images, measurements, metadata, and documentation.
In this context, we can begin to think of this enriched digital representation as a digital twin of the manuscript.

Fig. 2.1 Folios 22v and 23r of the Codex Manesse, Zürich, circa 1300-1340. Heidelberg University Library (Public Domain). https://doi.org/10.11588/diglit.2222#0041
Heritage Digital Twins (HDT)
The ECHOES Glossary defines heritage digital twins as “complex, organized, digital information (including but not limited to data, metadata, paradata, workflows) about a real-world heritage asset, encompassing its tangible and intangible components, allowing for documentation, preservation and analysis”.
In practice, this means that a digital twin is not just a photograph or a model. It is a structured digital representation of a heritage asset, which brings together different kinds of information about that asset and the processes through which this information was created. For your manuscript, this can include not only images, but also metadata, conservation reports, historical notes, and potentially 3D representations.
The value of a digital twin lies not simply in listing information, but in organising it so that the manuscript becomes easier to study, compare, and reuse in digital environments. The accompanying documentation makes clear what was captured, how it was captured, and what may be uncertain or incomplete.
More immersive outputs, such as historically reconstructed game environments or virtual exhibitions, are not automatically digital twins in themselves. However, they may be built on digital-twin data when they use documented images, spatial models, rich metadata, historical sources, and scholarly interpretation to create an interactive representation of a heritage asset or setting. In that sense, they can be understood as applications or experiential layers built from, or connected to, a digital twin.
Interoperability
Once your museum decides to share your beautiful manuscript beyond the institution, a new challenge appears: different systems may store, describe, and organise data in different ways.
For example, one system might record the manuscript’s date as “mid-14th century”, while another may say “circa 1350”. One database may describe the script type using a controlled vocabulary, while another may use free text. Even when the information refers to the same object, it may not be immediately compatible.
That’s why simply sharing data is not enough. For the manuscript to be truly discoverable and reusable, different systems need to be able to interpret and connect this information correctly. This is where interoperability becomes important.
The ECHOES Glossary defines interoperability as “the actions necessary to ensure that services, applications, and tools can work with one another and that datasets can be used seamlessly regardless of origin, format, or the descriptions they carry, in a way that does not depend heavily on human involvement.”
In practice, interoperability operates at different levels.
At the level of meaning (or so-called semantic interoperability), the question is whether different ways of describing the same concept can be mutually linked. If a researcher searches for a “codex,” will your system also return items described as “manuscripts”? If one catalogue uses “illuminated manuscript” and another uses “decorated codex,” can a search tool recognise that these are closely related descriptions? Achieving this kind of alignment often requires shared vocabularies and conceptual models. One such example is CIDOC CRM, a cultural heritage ontology: in simpler terms, it’s a shared framework for describing cultural heritage objects, people, places, events, and the relationships between them. It helps different institutions connect information even when their local catalogues use different structures or terms.
At the level of structure (or so-called syntactic interoperability), the question is whether data created in different technical formats can be exchanged and processed by different systems. For example, one institution might provide metadata as CSV, a spreadsheet-like table; another as JSON, a compact data-exchange format commonly used by web applications; and another as RDF, a specific format designed to describe relationships between entities in machine-readable ways. If one institution provides metadata in CSV, another in JSON, and a third in RDF, can these representations be translated or mapped into forms that other systems can understand and process?
Data Models
Interoperability allows different systems to exchange and interpret data. But for this to work consistently, there also needs to be an agreement on how information is structured in the first place.
When a museum catalogue records information using fields such as object name, date, material, provenance, or current location, it is making decisions about what kinds of information matter, how they should be organised, and how they relate to the object being described.
Different institutions may structure information about the same manuscript in different ways. One museum might describe the manuscript as a single object with one catalogue record, while another might divide it into smaller components, such as folios, bindings, illuminations, or annotations, each with their own records and relationships. One system may record the manuscript’s creator as a free-text field, while another may connect that person to an authority record shared across multiple collections.
A data model provides the underlying structure that makes these decisions explicit and consistent: a conceptual blueprint that defines how information is structured and how entities relate to one another. A data model defines what kinds of entities exist (for example, manuscripts, people, places), what properties they can have (such as date, material, or location), and how they relate to each other.
For the manuscript, this means being able to represent not just the object itself, but also its relationships to its creators, readers, place of origin, and to other related objects or collections.
When shared data models are used, these relationships can be expressed consistently across institutions. This makes it easier to connect collections, integrate data into tools and platforms, and support more complex forms of search, analysis and interpretation.
Digital Ecosystem
Now, let’s widen the lens. Your manuscript could potentially have a wide audience. A conservation laboratory may want to analyse pigment composition. A digital humanities research group may want to train an AI model to identify scribal hands. A school teacher may want to build a virtual exhibition for their students. An archaeologist may want to connect place references in the manuscript to excavation sites and gazetteers.
Together, these actors, tools, services, standards, and infrastructures form part of a digital ecosystem.
The ECHOES Glossary defines the digital ecosystem as “an open, adaptable, distributed and interoperable infrastructure that connects actors, activities, and cultural heritage objects through a user-friendly and unified graphical user interface designed to suit the needs of the fragmented CH communities”.
A digital ecosystem is broader than a digital commons. A digital commons comprises shared resources: data, tools, and knowledge that are made available for reuse under common rules. A digital ecosystem includes everything that surrounds and sustains their use: the institutions and communities that contribute to them, the platforms that host them and the processes through which they are interpreted, connected and reused.
Exercise
Take a moment to test your understanding of the material covered so far.
Complete the passage below using the concepts introduced in this section.
A structured representation produced by the museum’s digitisation department, which combines images, documentation, metadata, and provenance is called a . If the museum shares these resources under clear conditions that enable reuse, the manuscript becomes part of a . Once shared, the manuscript can only travel and “connect” if other systems can understand it, which is why and matter: they provide the shared meanings and shared structures that allow data to be discovered, linked, compared, and processed across institutional boundaries. When this begins to happen at scale, with many institutions, communities, infrastructures, and services interacting around shared resources, we can speak of a .
Conclusion
In this unit, we followed a manuscript as it transformed from being a physical object to becoming a connected digital resource. Along the way, we introduced a set of key concepts — digital twins, digital commons, interoperability, data models, and digital ecosystems — that together describe the foundations of the ECCCH. These concepts are not only about abstract and complex ideas about fairly technical matters: they also highlight practical ways in which data, tools, and people can come together in cultural heritage practice. In the next unit, we will focus on collaboration, and explore how these connections take shape through interactions between people, institutions, and technologies.
Supplementary reading
- IBM Think — What Is a Digital Twin?. A clear, well-written explainer from IBM covering the concept, how it works, and real-world applications. No technical background required. In many languages.
- Britannica — Digital twin: Definition, History, Types & Facts A good encyclopedic entry that covers history, types, and uses in plain language, a solid general reference.
- Twinview Insights — Preserving the Past Through the Future: How Digital Twins Are Transforming Heritage Conservation. This is the most accessible non-scientific piece specifically on the heritage application: it explains the concept clearly and covers conservation use cases like monitoring historic buildings and replicating lost artefacts.
- ACM Computing Surveys (2024/2025) — Digital Twins for Cultural Heritage: A Systematic Analysis of the State of the Art https://dl.acm.org/doi/10.1145/3793541. A comprehensive survey of 108 studies (2002–2025) that organises the field around three dimensions: user-facing applications, enabling technologies, and maturity levels. It also introduces a clear conceptual framework that distinguishes a basic digital replica from a true dynamic digital twin, useful for anyone seeking a rigorous definition grounded in the heritage domain.
Unit 3: Collaboration in the Cloud
In the previous unit, we started exploring how cultural heritage data can be structured, shared and connected. But even the most beautiful and treasured medieval manuscript does not create collaboration on its own. Collaboration happens when people, institutions, and tools interact around objects: interpreting them, enriching them, and using them in different contexts.
Cultural heritage work has always involved many different actors, often working in multidisciplinary and transdisciplinary teams to preserve, provide access to, and interpret the human record. Yet, despite the lofty promises of digital transformation, working in digital environments can still be slow, uneven, and difficult, especially when tools are scattered or when data remains locked in institutional silos.
The Cloud aims to change this by establishing a secure, federated environment where people, institutions, and computational services can work together more effectively.
In this unit, we will explore what collaboration the Cloud makes possible, and what this means for professionals across the cultural heritage sector.
From Individual Digitisation Projects to Shared Services
For many years, digitisation has largely been organised through individual projects. Each institution developed its own tools, workflows, and metadata practices. While these efforts produced valuable digital collections, they often remained difficult to compare or sustain over time. As a result, knowledge remained fragmented, and similar technical solutions were repeatedly built from scratch.
The ECCCH is designed to support a gradual shift away from this model, toward one based on shared, interoperable services. Instead of working in isolation, institutions can contribute to and benefit from a common infrastructure.
In this emerging model:
- tools can be reused rather than rebuilt;
- metadata can align with shared vocabularies and standards;
- data produced in one context can be explored, linked, and reused in others;
- institutions can retain control of their data while benefiting from shared services and infrastructure.
Although this model is still evolving, its direction is clear. By reducing duplication, improving interoperability, and strengthening sustainability, the Cloud aims to increase the collective impact of digitisation efforts across Europe. Collaboration, therefore, becomes an ongoing, infrastructure-supported process.
What Collaboration Means in the Cloud
In practice, collaboration in the Cultural Heritage Cloud takes many forms. Professionals work together across different stages of working with data. They produce, use and reuse data as part of their everyday activities, while also interpreting and enriching it to add context, meaning, and value. At the same time, computational tools assist in processing and analysis, and institutions coordinate access to collections and services.
These different forms of interaction are closely related. A curator may annotate an object, a machine-learning tool may suggest links to related materials, and another institution may provide access to complementary datasets.
In other words, we can think of collaboration in the Cloud as operating across three interconnected dimensions:
- collaboration between professionals working together (by sharing a common online space, a common set of datasets and a common set of applications);
- collaboration between humans and machines (by executing various tasks using
- some automated technologies, e.g. AI); and
- collaboration between institutions through shared infrastructure and standards.
These layers reinforce one another. Effective collaboration depends not only on people working together, but also on the tools that support them and the institutional frameworks that make shared access possible.
Human ↔ Human Collaboration
At its core, collaboration in the Cultural Heritage Cloud is about people working together on shared materials. This may involve interpreting objects, enriching metadata, annotating images or 3D models, or building thematic collections.
In the Cloud, these activities take place in shared digital workspaces, where multiple users can contribute to the same dataset over time. Instead of exchanging files or maintaining separate copies, professionals can work on a common resource, seeing each other’s contributions and building on them.
This approach supports collaborative creation and interpretation. Contributions can be tracked and attributed, changes can be reviewed, and different perspectives can be combined into a richer and more transparent record of knowledge.
Human ↔ Machine Collaboration
Many tasks in cultural heritage work are repetitive or time-consuming: transcribing handwritten texts, identifying places or people, linking related objects, or cleaning and aligning metadata.
In the Cultural Heritage Cloud, computational tools are designed to support these activities. Rather than replacing human expertise, they assist users by suggesting connections, identifying patterns, or proposing improvements.
For example, a transcription tool may help convert handwritten text into machine-readable form, or an entity recognition service may suggest links between a manuscript and related places, people, or collections.
However, these suggestions always require human interpretation and validation. Professionals remain responsible for reviewing results, deciding what is relevant, and ensuring the quality and meaning of the data.
This human-in-the-loop approach allows people to work more efficiently while retaining control over interpretation and decision-making.
Organisation ↔ Organisation Collaboration
Collaboration in the Cloud also takes place between institutions. Museums, archives, libraries, and research organisations often hold related materials, but their collections are stored in separate systems and described in different ways.
The ECCCH is designed to connect these distributed collections without requiring institutions to centralise or transfer their data. Instead, it relies on shared standards, a common data model, and connecting services that allow different systems to communicate and exchange information. A key part of this is the Heritage Digital Twin Ontology (HDTO), which provides a shared semantic framework for describing cultural heritage objects, their context, and their relationships. This ensures that data from different institutions can be understood and connected consistently.
Institutions do not need to operate fully interoperable repositories already. The Cloud supports this process by helping align data with a shared model, making existing collections progressively more compatible. Each organisation continues to manage its own data, while benefiting from a shared environment for collaboration.
In other words, the data stays where it is, but becomes part of a shared environment. This allows institutions to collaborate while retaining ownership and responsibility for their collections. It also makes it possible to provide controlled access to data, so that collaboration can take place securely and in line with legal and ethical requirements.
This approach also lowers the barrier to participation. Institutions of all sizes can participate, including smaller organisations that may not have the resources to build their own extensive technical infrastructure, but can still connect their data to shared services and collaborate with others.
Exercises
Take a moment to test your understanding of the material covered so far.
Conclusion
In this unit, you explored how collaboration works in the European Collaborative Cloud for Cultural Heritage and how it differs from more traditional, fragmented approaches.
Collaboration in the ECCCH is not a single action, but an ongoing process supported by shared infrastructure. As data is created, enriched, and connected across contexts, collaboration becomes part of everyday work rather than a separate step.
Understanding how collaboration works also raises important questions about how data should be shared, accessed, and reused responsibly.
The next unit introduces the principles of Open Science and FAIR data, which provide the conceptual and ethical framework for making collaboration sustainable, transparent, and reusable over time.
Unit 4: Open Science and FAIR Principles
This unit introduces two key approaches that shape how research is conducted and shared today: Open Science and the FAIR principles, and why they matter in the context of cultural heritage.
These approaches are not only technical frameworks. They reflect a broader shift in how knowledge is created, shared, and used. When cultural heritage data is well structured and made available responsibly, it can strengthen collaboration, support education, and enable creative reuse. It can also contribute to more transparent and inclusive access to heritage, which can, in turn, generate wider societal benefits by allowing educators, researchers, policymakers, and the general public to engage with and build on existing knowledge.
At the same time, however, openness raises important questions about copyright, sensitive materials, community rights, and the potential misuse of data. Open Science, therefore, combines opportunity with responsibility.
What is Open Science?
Open Science is an approach to research that aims to make knowledge more transparent, accessible, and reusable. It promotes sharing not only publications, but also data, methods, and tools – across disciplines and communities.
However, Open Science is not only about making data openly available. It also encourages opening processes, methods, and technologies, while respecting rights, communities, and local knowledge.
To work in practice, Open Science depends on shared infrastructures, such as repositories, standards, and governance frameworks, that support responsible data sharing. Without these, openness would remain an aspiration rather than a daily practice.
Open Science in Cultural Heritage
In the cultural heritage sector, Open Science extends existing practices of sharing and documentation into digital environments. It provides a framework for making data, methods, and processes more transparent and reusable, while respecting legal and ethical constraints.
In practice, this includes:
- sharing digitised collections and research outputs with clear rights information;
- documenting how and by whom data were created, analysed or interpreted;
- using shared infrastructures and standards where possible; and
- enabling contributions from diverse communities, including creative practitioners, students and local knowledge holders.
The ECCCH supports this approach by embedding these principles into its design, so that responsible sharing becomes part of everyday workflows rather than an additional step. Understanding these principles will help you make informed decisions about how to share, document and manage your own work within the Cloud.
What are the FAIR Principles?
The FAIR principles provide a practical way of applying Open Science. Originally developed for research data, the FAIR principles are now widely applied to many kinds of digital cultural heritage resources, including collections, metadata, images, texts, and 3D models. FAIR stands for: Findable, Accessible, Interoperable and Reusable.
These principles ensure that digital heritage assets can be discovered, understood, and used by people, institutions, and, increasingly, by machines.
FAIR does not mean that all data must be open. Sensitive collections, restricted materials or community-managed knowledge can still be FAIR, even if access is controlled. In this sense, FAIR is about clarity, structure, and long-term usability, rather than openness alone. When data adhere to the FAIR principles and are additionally made available under an explicitly open license, this is sometimes referred to as FAIR and Open (FAIR/O) data.
Following is a summary of the four FAIR principles. If you are interested in more detailed information, you can find that in the “Supplementary reading”.
Findable
Your data should be discoverable by others. This means that people need to be able to search for it and identify it clearly, even if they were not previously aware of your collection.
This typically requires persistent identifiers (such as digital object identifiers / DOIs or handles) so that others can reliably reference your data; rich descriptive metadata so that keyword searches can surface your data effectively; and indexing in searchable catalogues that encompass multiple datasets, so that your data can be discovered in broader contexts with others.
Unlike local inventory numbers used within a single institution, persistent identifiers are designed to function reliably across systems and over long periods of time.
Accessible
Your data should be clearly available and obtainable. This means that others can understand how to access your data and under what conditions it can be used.
Accessible does not mean that all data must be open. In some cultural heritage contexts, access may be restricted for legal, ethical, or conservation reasons. What matters is that access conditions are transparent and clearly defined. Metadata should remain accessible wherever possible, although some metadata elements may also need to be limited if they reveal sensitive information.
Interoperable
Your data should be able to connect with other data. This means that it can be understood and used across different systems, institutions, and contexts.
As discussed in Unit 2, interoperability allows different datasets and systems to work together by using standard formats and shared vocabularies. In cultural heritage, this is especially important because collections are distributed and described in different ways.
Reusable
Your data should be usable beyond its original purpose. This means that others can understand it, trust it, cite it, and apply it in new contexts over time.
Reusability depends on clear documentation. This includes how the data was created, what it represents, and under which conditions it can be reused.
Real-world Examples of FAIR Datasets
The following examples show how cultural heritage organisations apply FAIR principles in real-world contexts. They cover a range of scales, from individual institutions to national and European aggregation platforms:
- Rijksmuseum Open Data (Netherlands) - Museum collection open data providing structures metadata and openly licensed images through an API to support research, education and creative reuse. [https://data.rijksmuseum.nl/]
- CITiZAN: Coastal and Intertidal Zone Archaeological Network, Museum of London Archaeology (United Kingdom) - Citizen-science dataset documenting coastal heritage at risk, archived with a DOI and structured metadata in the Archaeology Data Service repository to support long-term preservation and reuse. [https://doi.org/10.5284/1116909]
- Gallica, Bibliothèque nationale de France (France) - National library platform offering digitised heritage collections with persistent identifiers, structured metadata and services that support discovery and reuse. [https://gallica.bnf.fr/accueil/en/html/accueil-en]
- SOCH (Swedish Open Cultural Heritage / K-samsök) (Sweden) - National heritage aggregation service exposing museum and archive metadata through open interfaces and linked data services to enable cross-institutional discovery. [https://www.raa.se/in-english/digital-services/about-soch/]
- CHERISH UAV Coastal Heritage Dataset (Digital Repository of Ireland) (Ireland) – Geospatial and UAV survey datasets documenting coastal heritage at risk, archived with structured metadata and persistent identifiers to support long-term preservation and research reuse. [https://repository.dri.ie/catalog/g158r977f]
- Europeana (Pan-European) – European platform aggregating cultural heritage metadata from thousands of institutions using shared data models and linked data principles, supporting large-scale discovery and reuse where licensing allows. [https://www.europeana.eu/en]
FAIR in the Cloud
The European Cultural Heritage Cloud is designed to support FAIR principles in practice. Rather than treating findability, accessibility, interoperability, and reusability as separate tasks, the Cloud embeds them into shared workflows, data models, and services.
This means that, as you work with data in the Cloud, many aspects of FAIR are supported by design: through structured metadata, shared standards, and tools that enable connection and reuse across collections.
In this way, FAIR becomes part of everyday practice. It helps ensure that your work remains visible, usable, and meaningful over time, both by colleagues and by automated tools.
Focus on Standards
In Unit 2, we introduced data models as ways of structuring information, defining, for instance, what kinds of entities exist (such as objects, people, or places) and how they relate to one another.
But simply having a data model or organising your data based on your own, self-defined data model may not be sufficient. After all, each institution could develop their own data models. Sharing and clearly documenting that model would be an important first step towards interoperability. But if many different, bespoke data models are used, integrating data across institutions and systems becomes much more difficult.
This is where standards come into play: they provide shared and agreed ways of structuring, describing, and exchanging information across systems and communities. In other words, a data model describes the structure of information, while a standard reflects a broader community agreement on how that information should be represented and exchanged.
Standards Relevant to the ECCCH
The following examples illustrate some of the most widely used standards in the cultural heritage domain. Standards are agreed frameworks, specifications, or conventions that ensure information is created, structured, described, and shared in a consistent and interoperable way. While it is not necessary to learn them in detail at this stage, it is useful to recognise their names and understand their roles.
- Conceptual models, such as the CIDOC Conceptual Reference Model (CIDOC CRM), the Library Reference Model (LRM), the Records in Contexts Conceptual Model (RiC-CM) or the Europeana Data Model provide the means to organise the information about cultural heritage assets and their contexts. The ECCCH builds on this approach: the CIDOC-CRM serves as the basis for its Heritage Digital Twin Ontology (HDTO), which you will encounter later in Unit 5.
- Metadata standards, such as Dublin Core or domain-specific standards like MARC21 (Machine-Readable Cataloging), EAD (Encoded Archival Description), or Lightweight Information Describing Objects (LIDO) give structure and meaning to cultural heritage descriptions so that they can be discovered and understood.
- Some standards also support the enrichment of data through annotations. For example, the Web Annotation Data Model allows users to attach comments, interpretations, or links to specific parts of a resource, supporting collaborative analysis and interpretation.
- Vocabularies and thesauri such as the Getty Art and Architecture Thesaurus, the UNESCO Thesaurus, or Wikidata support consistent terminology, multilingual access and cross-domain discovery.
- Text encoding standards, such as the Text Encoding Initiative (TEI), provide detailed and flexible ways of representing textual materials, including manuscripts, inscriptions, and scholarly editions. TEI is widely used in digital humanities to encode the structure, content, and interpretation of texts in a machine-readable form.
Persistent Identifiers (PIDs) such as Digital Object Identifiers, Archival Resource Keys, or Handles, Uniform Resource Names or the International Standard Name Identifiers, provide a long lasting reference to objects, places, people and concepts.
In addition, technical registries, such as those documented by the PRONOM, help identify file formats and the software needed to access them, supporting long-term preservation and continued usability of digital heritage data. Technical protocols such as OAI-PMH support the exchange of metadata between systems, enabling collections to be aggregated and discovered across repositories.
You do not need to understand the details of each of these technical components. It is enough for you to recognise that they play an important role in enabling large-scale infrastructures such as the ECCCH. Another important point is that you will not need to become a technical specialist to benefit from these standards and protocols. The ECCCH is designed to help you apply them intuitively through shared tools, enriched metadata workflows and guidance that supports FAIR-by-design practice.
Exercise
Take a moment to test your understanding of the material covered so far.
Conclusion
Open Science and the FAIR principles describe what responsible, sustainable digital heritage work should aim to achieve. However, principles alone are not enough; they require infrastructure to become operational in practice. The Cloud is being designed to operationalise these ideas by embedding findability, accessibility, interoperability and reusability directly into its technical architecture. In this way, responsible openness becomes not only a technical choice, but a contribution to the long-term visibility, resilience and public value of cultural heritage.
In the next unit, we will look more closely at how this is implemented in practice, exploring how the Cloud’s architecture and services support these principles through concrete tools and workflows.
Supplementary reading
The resources below provide a small selection of key references if you would like to explore Open Science and FAIR principles in more depth.
You do not need to read all of these. You can select one or two depending on whether you are interested in policy context, conceptual understanding, or practical guidance.
- Wilkinson et al. (2016) - The FAIR Guiding Principles for scientific data management and stewardship. A foundational text introducing the FAIR principles and explaining their role in improving data management and reuse. https://doi.org/10.1038/sdata.2016.18
- GO FAIR Initiative - FAIR Principles overview. A clear and accessible explanation of each FAIR principle with practical examples and guidance. https://www.go-fair.org/fair-principles/
- European Commission - Open Science Policy. An overview of how Open Science is embedded in EU policy and research frameworks. https://research-and-innovation.ec.europa.eu/strategy/strategy-research-and-innovation/our-digital-future/open-science_en
- UNESCO Recommendation on Open Science (2021). A global policy framework outlining principles, values and approaches to Open Science across different contexts. https://unesdoc.unesco.org/ark:/48223/pf0000379949
- OpenAIRE - How to make your data FAIR. A practical guide with concrete steps and examples for applying FAIR principles in research and data management. https://www.openaire.eu/how-to-make-your-data-fair
Unit 5: How the ECHOES Collaborative Cloud Works
In the previous units, we introduced the European Cultural Heritage Cloud as a shared environment for working with cultural heritage-related data. We explored how data can be structured, connected, and made reusable, and how collaboration can take different forms across people, institutions, and tools.
But how will all this actually work in practice? What will it feel like to use the Cloud? How will different components of the Cloud come together? What kinds of steps will users need to take, and what will they need to understand along the way?
To answer these questions, in the rest of this unit, you’ll follow three fictional user stories. Each story shows how different parts of the Cloud are designed to work together.
User Story: Making a Collection Available in the Cloud
Persona: Claire Hewitt - Collections Steward
Role: Curator at a mid-sized regional museum
Claire works as a curator at a mid-sized regional museum. She manages a digitised collection from her institution’s regional history archive and wants to make it discoverable and interoperable with other European collections, while maintaining her institution’s data quality standards.
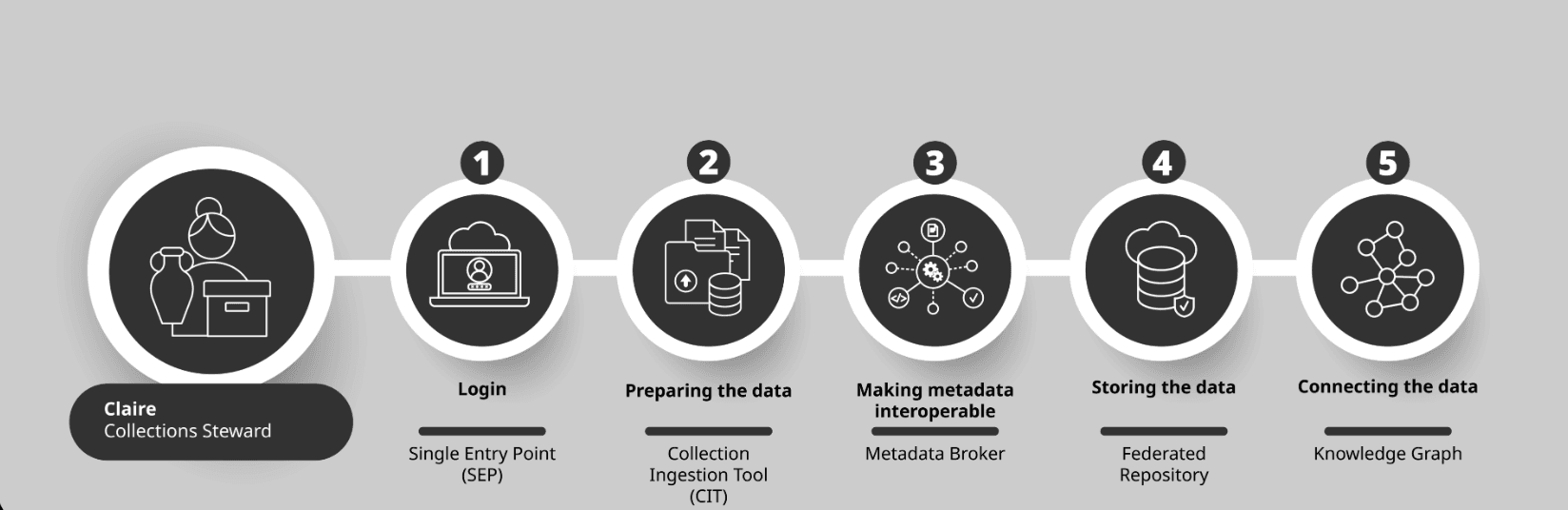
Fig. 5.1: Claire contributes her collection to the Cloud through a structured workflow: logging in via the SEP, preparing her data using the Collections Ingestion Tool, making her metadata interoperable through the Cloud’s translation services, having her collection stored in her own repository while enabling connections with other collections through the Cloud’s Knowledge Graph.
Step 1: Logging in - The Single Entry Point (SEP)
Claire accesses the Cloud and logs in via a web browser using her institutional account. She does not need to create a new username and password. Once authenticated, she can move between different services without logging in again. She can only see and access the services she is authorised to use, based on her institutional role and permissions.
This is enabled through federated identity and authentication mechanisms, which connect existing institutional and academic identity providers (e.g. ORCID, eduGAIN). These identities are recognised by her institution, meaning access rights and responsibilities can be managed through her existing organisational affiliation rather than separate Cloud-specific accounts.
The Single Entry Point (SEP) refers to this unified access experience across services. It is broader than a simple login mechanism and supports seamless navigation across the Cloud ecosystem (see glossary entry for SEP).
Step 2: Preparing the data
Claire prepares and structures her collection using tools provided by the Cloud. Instead of working in isolated spreadsheets or local databases, she works within an environment that interacts directly with the Cloud’s Knowledge Base and Knowledge Graph – the core components that support the structuring, linking, and integration of data across the infrastructure.
She uses the Collection Ingestion Tool (CIT), which is currently being developed as part of the ECHOES project. The CIT does not create or duplicate databases; instead, it generates and manages catalogue views by interacting with these underlying components and existing data structures.
This type of specialised tool is known as a vertical application: within the ECHOES infrastructure, this means a cross-layer application – typically with a graphical user interface – that integrates components from multiple architectural levels to support an end-to-end professional workflow. In Claire’s case, the CIT brings together data access, transformation, and interaction with the Knowledge Graph in a single environment tailored to cataloguing tasks.
Step 3: Making metadata interoperable
Claire’s museum already uses its own metadata schema. The Cloud does not require institutions to abandon their existing systems.
Instead, interoperability is achieved through metadata transformation mechanisms. In some cases, a component called a metadata broker (translator) can be used to map local metadata into the shared model used across the Cloud. However, this is not an automated or default process, and it is typically considered a fallback solution. Where possible, institutions are encouraged to adopt the Heritage Digital Twin Ontology (HDTO) directly to minimise transformation effort and improve long-term interoperability.
Unlike the API Gateway, which handles requests, the metadata broker works on the data itself, ensuring that information can be interpreted consistently across systems while preserving its original structure.
This allows Claire’s collection to connect with others without losing its original structure or meaning. As we saw in unit 2, this is what interoperability is about.
Step 4: Where the data is stored - Federated repositories
Claire’s collection is not moved into a single central database. Instead, it remains in her institution’s repository while being connected to the wider Cloud environment.
This approach is known as federation: data remains under local institutional governance while being accessible within a connected infrastructure, provided that participating repositories meet the Cloud’s technical and semantic requirements.
Federation enables collaboration without centralising ownership, allowing institutions to retain control over their data while participating in shared discovery and access frameworks.
Step 5: How data connects with other data - the Knowledge Graph
Once Claire’s data is integrated, it can become part of the Knowledge Graph, provided it meets the required modelling and interoperability standards.
The Knowledge Graph does not simply reveal connections automatically. Instead, it enables the discovery of relationships that already exist or can be inferred through structured linking of people, places, events, and objects across datasets.
For example, if Claire’s collection includes an artefact related to a historical figure, and that figure also appears in another collection that’s linked to the Cloud, the system can reveal that connection.
This type of linking between related bits of information about people, places, events and objects across different collections is made possible by the Knowledge Graph. Instead of treating datasets as isolated records, the Knowledge Graph allows them to be explored as part of a wider web of relationships.
This transforms Claire’s collection from an isolated dataset into part of a broader network of interconnected cultural information, supporting richer discovery and reuse across institutions.
User Story: Working Across Collections
Persona: Dr. Anna Olsen - Research Data Scientist
Role: Researcher at a university studying migration patterns
Anna is researching migration patterns across Europe. The materials she needs are scattered across multiple archives in different countries. She wants to search across collections, combine relevant sources, and build a coherent research dataset that follows FAIR principles, without navigating separate systems or manually aligning formats.
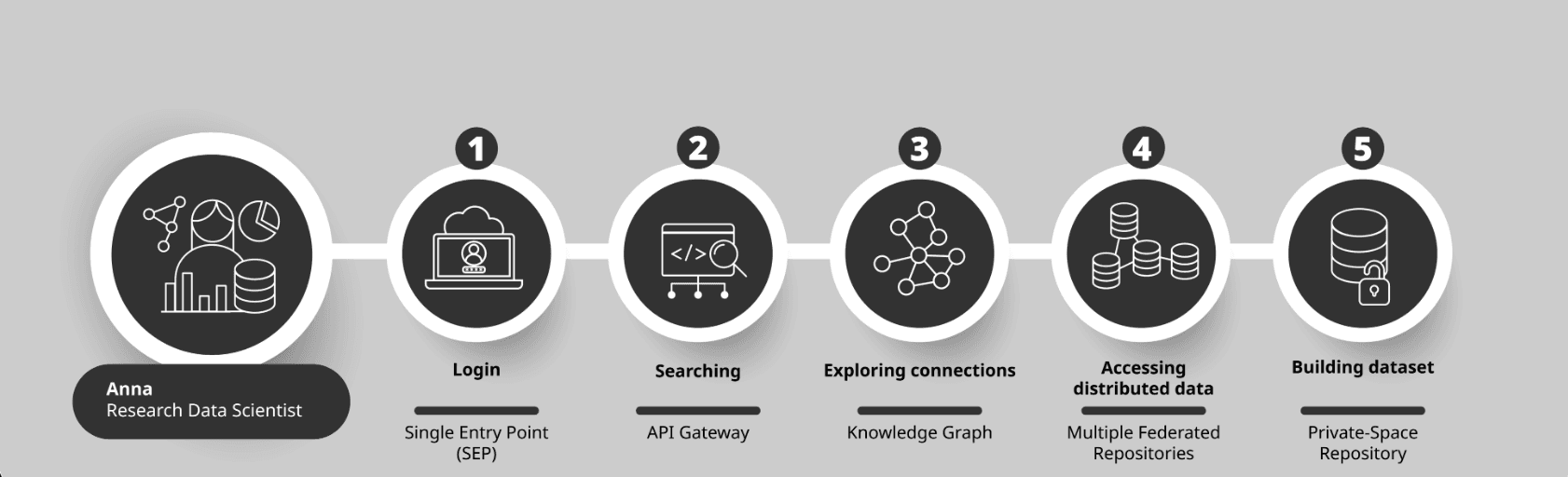
Step 1: Accessing the Cloud - logging in once
Anna enters the Cloud through the Single Entry Point (SEP) using her ORCID account. As with Claire, she signs in once and can move between different services without repeated authentication. She only sees and accesses the services she is authorised to use.
Step 2: Searching across collections - API Gateway
Anna enters her search query for migration-related materials once and retrieves results from multiple collections at the same time. She does not need to visit each archive separately or adapt her search to different systems.
Behind the scenes, the Cloud determines which collections and services are relevant to her query at runtime. The API Gateway plays a key role in this process. It acts as an interface between different components of the infrastructure, routing requests to appropriate services, handling authentication and access checks, and enabling communication between systems.
The API Gateway does not interpret or transform the data itself. Instead, it ensures that requests are correctly forwarded and that responses from different services can be returned in a consistent way to the user interface.
Step 3: Making sense of the connections: Knowledge Graph and HDTO
As Anna explores the results, she begins to see how the materials are connected to one another.
Records from different collections are mutually linked through shared references to people, places, events and objects, allowing her to follow relationships across collections.
These connections are made visible through the Knowledge Graph, which organises information as a network of connections. They rely on a shared conceptual framework that defines how different types of information relate to one another. Unlike the metadata broker, which aligns data formats, the Knowledge Graph reveals how the data is related.
For this purpose, the Cloud uses a framework called the Heritage Digital Twin Ontology (HDTO), which defines:
- what can be represented (objects, actors, locations, events, processes);
- how entities are connected;
- how provenance, transformations, and historical context are recorded.
Because these relationships are defined consistently in the Cloud, Anna can collect materials from different sources and use them in a large-scale comparative study.
Step 4: Working across collections - private workspace
As Anna builds her dataset, she works with materials stored in different institutional repositories. This you already saw in Claire’s case: the data remains where it is, while the Cloud allows it to be accessed and combined across collections.
To organise her work, Anna uses a private workspace within the Cloud. Here, she can gather selected materials, refine metadata, add annotations, and prepare her own dataset.
This workspace is designed for research in progress. It allows Anna to experiment, organise her data, and document her work before deciding what to share more broadly.
When her dataset is ready, she can choose to publish it into a shared repository, where it becomes, following FAIR principles, discoverable and reusable by others.
User Story: Working with 3D Models
Persona: Dr. Elena Novak - Domain/Subject Specialist Role: Conservator-restorer specialising in archaeological artefacts
Elena is working on a fragile archaeological artefact and has created a high-resolution 3D model of it. She wants to annotate the model with her observations and treatment plans, so that her conservation work is clearly documented, shareable with colleagues, and connected to the object’s digital twin.
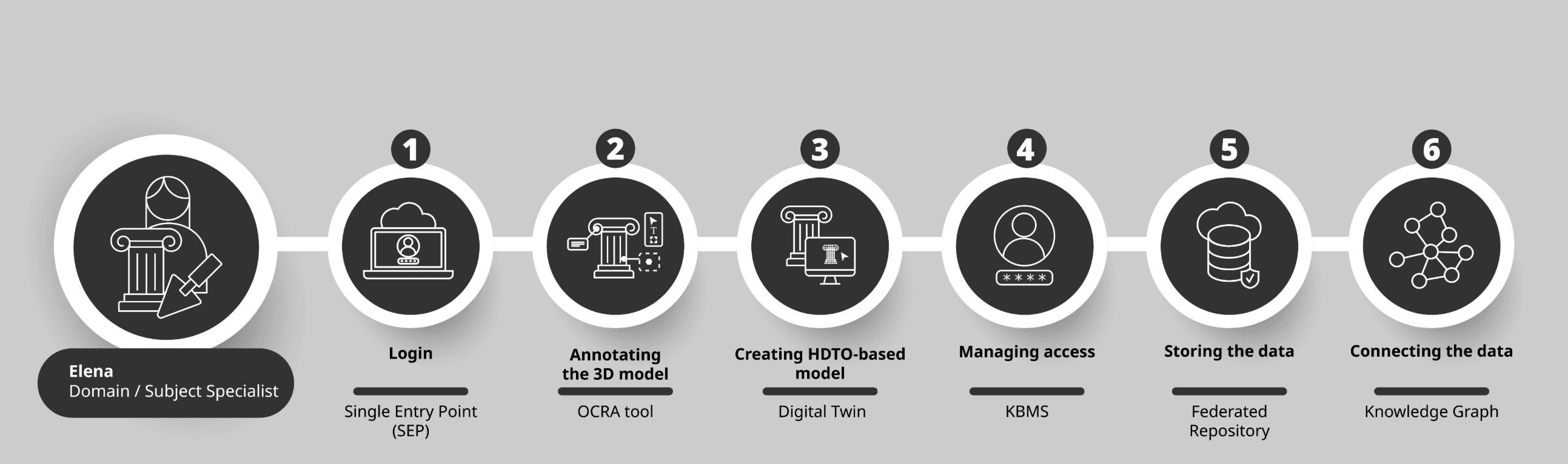
Step 1: Logging in
Elena enters the Cloud through the Single Entry Point (SEP).
Step 2: Annotating the 3D model with OCRA
After logging in, Elena opens a 3D annotation environment designed for conservation work. Here, she can examine the model: zoom into the surface, rotate the object, and select specific areas of the model.
Instead of writing a separate report disconnected from the artefact, she attaches observations directly to precise points or regions on the 3D model. Colleagues can later open the same model and immediately see what she observed and where.
This environment is provided by the Online Conservation Restoration Annotator (OCRA), a vertical application supporting conservation workflows.
Step 3: Contributing to the heritage digital twin
Elena’s annotations do not remain separate from the object. They become part of its digital representation.
A heritage digital twin, as you already learned earlier in this course, brings together different types of information about a cultural heritage object into a structured whole. This can include metadata describing the artefact, provenance and conservation history, related documentation and links to other objects or entities.
By adding her observations directly to the 3D model, Elena extends this digital twin. Her notes, interpretations, and treatment plans become part of a shared, evolving record of the object. This means that her work is not locked in a local report, but connected to the object itself and available to others working with it.
Step 4: Ensuring secure collaboration and traceability
Some of Elena’s observations are sensitive and should not be openly accessible. She needs to control who can view or edit her work, while still collaborating with trusted colleagues.
In the Cloud, this is handled automatically. Elena can share her work with selected users, knowing that access is managed according to defined permissions.
At the same time, her contributions are recorded and tracked over time. Changes can be reviewed, previous versions can be restored, and the history of the object remains transparent.
These functions of the Cloud are supported in part by the Knowledge Base Management System (KBMS), which manages the metadata layer, ensuring that contributions, permissions, and versioning information are structured and traceable. The underlying data itself is handled by other components of the infrastructure.
Step 5: Storing and connecting the data
The annotated model is stored within a federated repository, meaning Elena’s institution retains control over the data.
At the same time, the model and its associated information are connected to the wider Knowledge Graph, allowing the object to be discovered, linked, and studied in relation to other collections.
User Story: Transcribing Historical Manuscripts
Persona: Luca Minelli
Role: Early career explorer
Luca is studying a collection of fragile historical manuscripts stored across several European archives. Many of these documents are handwritten and cannot be easily searched or analysed. He wants to transform the manuscripts into structured, searchable text while preserving the source material and ensuring that his work follows FAIR principles
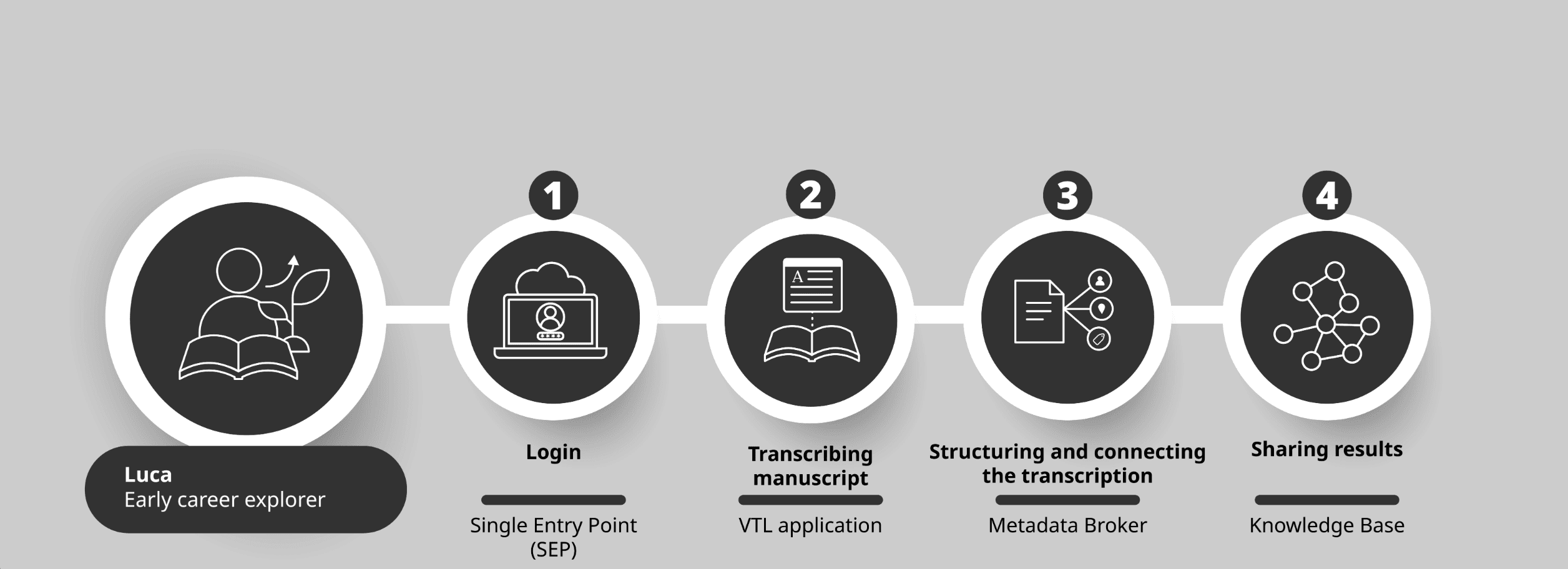
Step 1: Logging in
Luca accesses the Cloud using the Single Entry Point (SEP). With one secure login, he gains access to the tools and datasets he is authorised to use.
The SEP allows users to move between services without repeated authentication and while respecting institutional access policies.
Step 2: Working with manuscripts - the Virtual Transcription Laboratory
Luca opens the Virtual Transcription Laboratory (VTL), a specialised vertical application designed for textual heritage. It supports the transformation of handwritten material into structured digital text. Within the VTL, Luca can:
- view high-resolution images of manuscripts;
- apply automated text recognition suggestions;
- correct and refine results manually;
- align terms with controlled vocabularies;
- document uncertainties or historical context.
The VTL follows a human-in-the-loop approach. Computational tools assist by suggesting transcriptions, but Luca remains responsible for interpretation and validation. This ensures both efficiency and academic reliability.
Step 3: Structuring and connecting the transcription (HDTO)
As Luca works, his transcription is structured and connected to related information in the Cloud. It is linked to metadata describing the manuscript, including provenance, historical context, and references to people, places, and events.
This is enabled by the Cloud’s shared semantic framework (HDTO), which ensures that the transcription is not treated as an isolated text but as part of a wider network of knowledge. As a result, Luca’s work becomes searchable, linkable, and reusable across collections.
Step 4: Saving, managing and sharing results
Luca’s transcription is stored within the Cloud environment, where he can continue refining it in a controlled workspace before publication. Background services manage:
- access permissions;
- version history;
- contribution tracking.
When the transcription is validated, Luca can publish it to a shared repository, where it becomes part of the wider Knowledge Base and can be accessed and reused by others.
The Architectural Principles Behind the Cloud
The four user stories presented above are not isolated scenarios. Each of them illustrates how the Cloud is designed to support everyday work through a combination of shared architectural principles.
When Claire works in a shared cataloguing environment, she benefits from federation, which allows her institution to keep control of its own catalogue while connecting it to those of other institutions. At the same time, she works with a specialised tool – a so-called vertical application – which operates within the Cloud by integrating with its underlying services and components. This is enabled by modularity: an architectural approach in which the system is composed of distinct but interoperable components, allowing specialised applications to be developed and used for specific purposes while relying on shared services and standardised interfaces.
When Anna analyses distributed datasets, she relies on semantic interoperability: the ability to combine and interpret data from different sources in a consistent and meaningful way. This is made possible through the Heritage Digital Twin Ontology (HDTO), which provides a shared conceptual framework for describing and connecting cultural heritage data across institutions.
When Elena annotates a 3D model, she works in an environment that ensures both availability and scalability: the Cloud has been designed to provide stable and reliable access to services, while supporting increasing amounts of data and growing numbers of users without loss of performance.
Taken together, these principles - federation, modularity, semantic interoperability, availability, and scalability - show how the Cloud transforms architectural design into practical, robust, and trustworthy services that effectively support everyday work.
Exercise
Continuing the Journey
In the previous unit, we explored how the European Collaborative Cloud for Cultural Heritage will work in practice through a series of user stories. But the Cloud itself is still under active development. Its services, tools, and training ecosystem will evolve over time, through successive project phases, community contributions, and funded initiatives. For that reason, the most important next step is not to “master” the Cloud as it exists today, but to stay informed as it grows. The simplest way to do this is to follow ECHOES updates: you could start by subscribing to the ECHOES newsletter and regularly checking the project website, where new calls, tools, applications, and learning opportunities are announced as they become available.
One of the main ways to actively engage with ECHOES is through the Cascading Grants Programme. This programme supports projects that contribute data, tools, workflows, or applications to the Cultural Heritage Cloud. Rather than funding large, centralised developments, ECHOES is designed to grow through many smaller, distributed contributions from across the cultural heritage community.
The first two calls have already taken place, and they provide a useful indication of what is expected: clearly defined datasets or use cases, attention to interoperability and reuse, and a concrete benefit for a target community. A third and final call is planned, with a focus on data and vertical applications. For those considering applying, the most effective preparation is to begin early by identifying a dataset, workflow, or service that could be meaningfully connected to the Cloud, and by following the guidance provided on the ECHOES website.
Even if you are not planning to apply immediately, reviewing past calls, applicant guides, and FAQs is a useful way to understand how participation in the Cloud is structured, and what kinds of contributions are most valuable. And if you do plan to apply to the third call, you could write to grants@echoes-eccch.eu with grant-specific questions.
This course should be understood as part of a planned ECHOES Curriculum, designed to support different levels of engagement with the ECCCH. As the Cloud develops, this introductory course will be revised, and additional training materials will be released. These will include more specialised courses, practical guides, and hands-on resources. In particular, as vertical applications on transcription, conservation, or data ingestion mature and become available, dedicated training will be developed to support their use in real research and heritage workflows.
In that sense, you should look at this course not as an endpoint but as the beginning of a journey. The most effective way to continue the journey is to follow the development of ECHOES, return to updated materials, and engage with new learning opportunities as they emerge.
Satisfaction Survey