ELEXIS Pathfinder to Computational Lexicography for Developers and Computational Linguists
- Authors
- Topics
This learning resource provides software developers and computational linguists with an overview of the typical computational processing tasks and software tools in the lexicographic workflow. The resource introduces the most widely used custom developed tools for corpus-based lexicography as well as their functionality. Additionally, we give pointers to trending R&D topics in computational lexicography ranging from automatic extraction of good examples and word-sense disambiguation to machine learning. The course is aimed at developers and computational linguists who are new to lexicography and who quickly want to familiarise themselves with the most important literature and/or available learning resources which can bring them up to speed in the fast-changing field and prepare them to collaborate in a multidisciplinary team of lexicographers, computational linguists and software developers.
Learning Outcomes
Upon completion of this course, students/developers will be able to
- assess different tools used in the lexicographic workflow
- understand the typical functions and custom features of lexicographic software tools
- compare and evaluate different approaches to automatic extraction of lexicographic data (e.g. headword lists, collocations and example sentences)
- find the most important literature and/or available learning resources in computational lexicography
Tools in the lexicographic workflow
Two tools are more or less indispensable in a good lexicographic workflow, i.e. a dictionary writing system (DWS) and a corpus query system (CQS).
A DWS is a type of specialised software that is used to support the dictionary editing process whilst ensuring structural coherence and facilitating project management. A CQS is a tool that allows lexicographers to analyse, search, manipulate and save corpus data. It should be noted that lexicographers are probably the most demanding users of corpus query systems – they require and regularly use the highest number of features in CQS.
Another important type of lexicographic software that should be mentioned are dictionary user interfaces (UI). These are strictly speaking not part of the lexicographic production workflow and will not be discussed further here, but see e.g. Klosa-Kückelhaus & Michaelis (2022) for more on the design of internet dictionaries.
In the courses, Lexonomy: Mastering the ELEXIS Dictionary Writing System and LEX2: Mastering ELEXIS Corpus Tools for Lexicographic Purposes, you can learn how to use the DWS Lexonomy and the CQS Sketch Engine. In this pathfinder, we take a broader perspective. We describe in a nutshell what a DWS and a CQS is, what the main characteristics are and what kinds of systems there are and where you can find them.
Dictionary Writing Systems
What is a DWS?
The core function of a DWS is to support lexicographers in editing dictionary entries, relieving them of routine tasks and automating many procedures that had to be taken care of manually before. However, a DWS is much more than an editor. It is designed to manage the entire dictionary production workflow, from the first entry to the final product ready for publication in print or electronic format. In addition to an editing interface, it also includes a set of administrative tools for project management and publication.
Other English terms for a DWS that you may encounter, are dictionary editing system, dictionary compilation software, lexicography software or dictionary production software, lexicographic workbench, dictionary management system or lexicographer’s workbench, dictionary editing tool, dictionary building software, or simply editorial system.
What kinds of DWS are there and where can you find them?
Within the lexicographic community, different kinds of DWS are used:
- off-the-shelf systems
-
- commercial systems
- open-source systems
- in-house systems
- customised general-purpose XML editors
Examples of off-the-shelf commercial systems are products such as IDM DPS and TLex. Open-source systems include Lexonomy, FLex (Fieldworks), and LanguageForge. The latter two are mainly used in the area of field linguistics. In-house systems can typically be found in institutions which have a long tradition in lexicography. These institutions often use their own, dedicated DWS that has been developed exclusively for their purposes, e.g. EKILEX of the Estonian Language Institute and INL-DWS (see Tiberius et al. 2014) at the Dutch Language Institute. Examples of general-purpose editors which have been customised to the particular needs of a project are the XML editor oXygen (See the course Mastering oXygen XML Editor for Dictionary Nerds) and XMetal.
For a list of DWS that are currenty used in lexicography, see Kallas et al. (2019a: 19-21).
What are the main characteristics of a DWS?
To support the editing process, a DWS has an editing interface, often with a form-like presentation, which allows lexicographers to enter their text into predefined slots or spaces. Dictionary entries are highly structured objects with many recurring elements, e.g. headword, part of speech, sense, definition, translation (in bilingual and multilingual dictionaries), and examples.
Drop-down lists are generally used for elements which allow a limited number of values and character strings (e.g. possible values for part-of-speech could be noun, verb, adjective, etc. ). Furthermore, the editing interface should allow lexicographers to copy and paste text, for example from the CQS into the DWS, and to move fields or entire groups of fields, for example, to other parts of the entry or dictionary (including e.g. re-ordering and renumbering of senses).This requires automatic validation of the entry structure: if text elements are inserted in the wrong order, the system should alert the user. In addition, the system should alert the lexicographer when a headword is already present in the dictionary. A DWS usually offers one editing interface but several different ways of viewing the data, i.e. a view to explore the raw data together with the markup, a form-like view and a WYSIWYG view, previewing the entry as it may be shown in an online dictionary.
In addition to an editing interface, a DWS also offers ‘housekeeping’ tools that help to manage large projects, keeping track of progress against the working schedule and budget. This includes functionalities such as allocating a batch of entries to be compiled or edited by a particular lexicographer, keeping a record of who is working on which entries and the status of the entries (e.g. finished, in progress or not yet started). Furthermore, it should be possible to set different levels of authorisation so that, for example, freelance staff are allowed to edit only the dictionary project or entries they have been hired for. Other useful features are version control, track changes, and scriptability. Bulk operations can be useful to make the same correction to a whole set of entries with a single operation.
The ideal system is highly customisable, both in terms of functionalities and interface.
A DWS should also have good import and export facilities. It should support batch merges, allowing large amounts of data to be added to the system quickly and easily and it should be able to export the data from the system in different formats for further processing or publication. From the ELEXIS surveys (Kallas et al. 2019a,b; Tiberius et al. 2022) we learn that XML is still the most used exchange format. Some systems such as Lexonomy also allow online publication of the dictionary within the system.
As noted by Abel (2012) “A dictionary writing system should never be viewed in isolation, but rather within the framework of a specific dictionary project and its whole environment, including related projects, long term perspectives, etc.” This quote is even more important in the current situation. Over the past decades, the field of lexicography has undergone radical changes. A new trend can be observed which is characterised by linking, reusing and sharing of lexicographic data and thinking beyond individual dictionary projects.
These changes result in some additional requirements for a DWS, including:
- interoperability with other resources, operating systems and tools
- support for automatic data extraction
- possibility to link to other (external) sources
- API support
Corpus Query Systems
What is a CQS?
a tool that allows lexicographers to analyse, search, manipulate and save corpus data. It is should be noted that lexicographers are probably the most demanding users of corpus query systems – they require and regularly use the highest number of features in corpus tools
What kinds of CQS are there and where can you find them?
Similar to the DWS, different kinds of CQS are used within the lexicographic community:
- off-the-shelf systems
-
- commercial systems
- open-source systems
- in-house systems
Examples of off-the-shelf commercial systems are products such as Sketch Engine. Open-source CQS include systems such as Antconc, BlackLab, The IMS Open Corpus Workbench (CWB), Kontext, Korp, and NoSketch Engine.
What are the main characteristics of a CQS?
Features offered by corpus tools vary significantly, but all the tools offer at least the concordance, which is the main basic feature of corpus tools and represents the essence of corpus interrogation for lexicographers. As defined by Kosem (2016), “the concordance is a listing of the occurrences of a searched item, with each occurrence shown with a surrounding context.”

Figure 1: concordances for the query ‘word’ in the ukWac corpus in the Kontext CQS.
Concordance lines can be displayed in two ways, as sentences, or in the KWIC (Key Word in Context) format, with the lines centred according to the searched item. In the above example the concordances are displayed in KWIC format.
Differences between different corpus tools can be found at the level of complexity offered for conducting searches in the corpus, ranging from simple search options (i.e. searching for a word or a lemma, combined with information on the part of speech) to advanced search options including the use of Corpus Query Language (CQL), a full featured query language allowing to search for complex patterns. An introduction to the use of CQL in Sketch Engine can be found here.
Other features offered by corpus tools involve some type of statistical calculation, for example word lists, collocations, synonyms and so forth (see Section 4 in the course Introduction to Corpus-Based Lexicographic Practice for more and Atkins and Rundell 2008:108). Among the more advanced features and highly valuable to lexicographers, are detailed collocation presentation (lexical profiling), good dictionary example identification tool, and tickbox lexicography.
Lexical profiles
A lexical profile is a kind of statistical summary which reveals the salient facts about the way a word most typically combines with other words. It provides a compact and revealing snapshot of a word’s behaviour and uses. The word sketches in Sketch Engine are a type of lexical profile, providing collocate lists per grammatical relation.
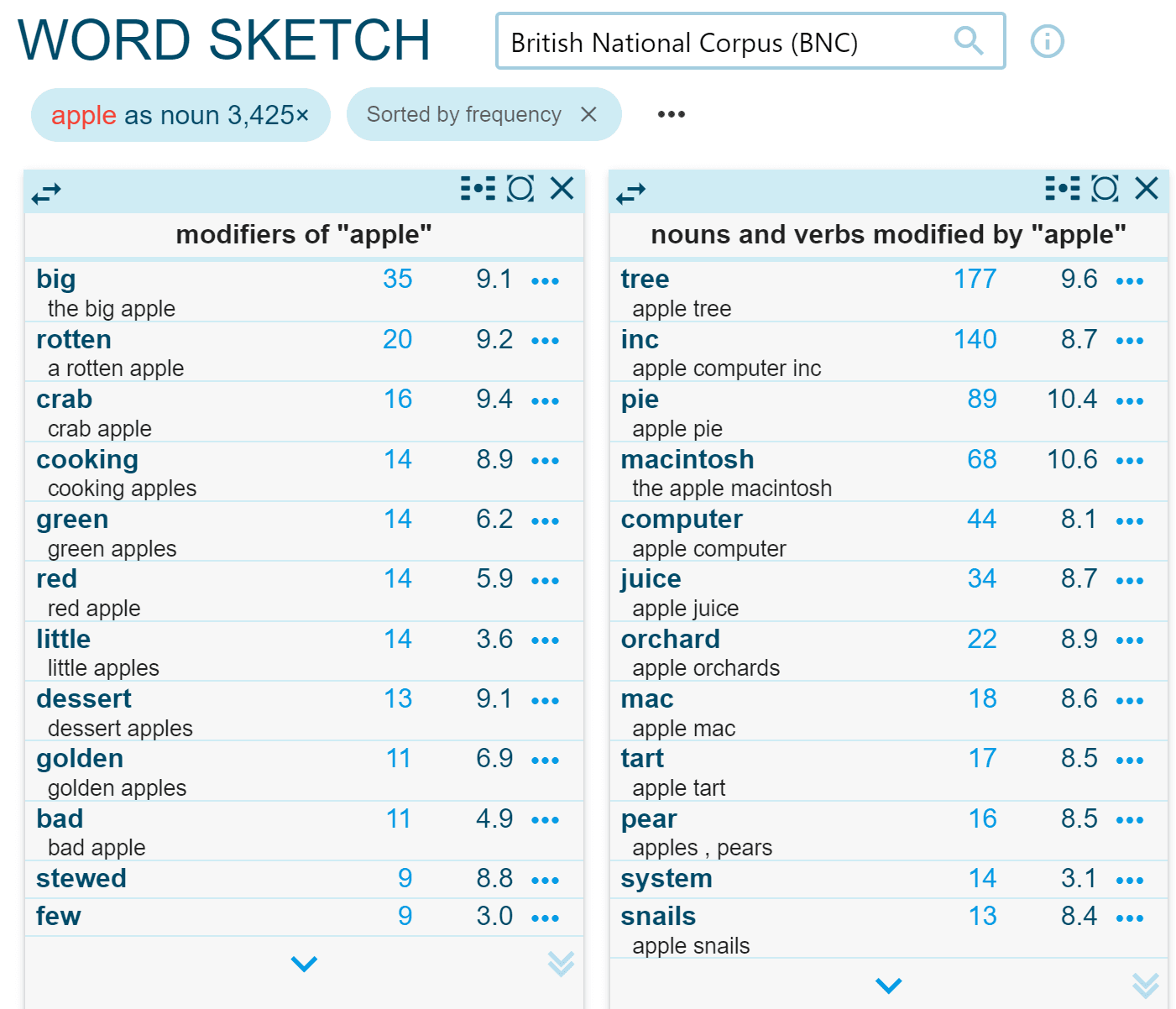
Figure 2. Part of the Word Sketch for the noun apple.
Word sketches are based on a Sketch Grammar which consists of a series of rules written in CQL that search for collocations in a text corpus and categorise them according to their grammatical relations, e.g. objects, subjects, modifiers etc. For more information on how to write such a Sketch Grammar, see: https://www.sketchengine.eu/documentation/writing-sketch-grammar/
Word sketches together with the concordances provide the lexicographers generally with enough information to determine the different meanings of a word. In the above extract from the word sketch for apple, some collocates are clearly related to the fruit sense of apple, whereas collocates such as computer and mac are clearly related to the products of the American multinational technology company.
Good dictionary example identification
Another useful feature for lexicographers is the automatic identification of good example sentences. GDEX in Sketch Engine is such a function. It automatically sorts the sentences in a concordance according to their usability as an example sentence in the dictionary based on a set of quantifiable heuristics, such as sentence length, frequency of words and blacklists of vulgar words. This way, the best example sentences will appear at the top of the concordance list, and they’re the ones lexicographers see first. The difference of the concordance display with and without GDEX is illustrated below for apple.
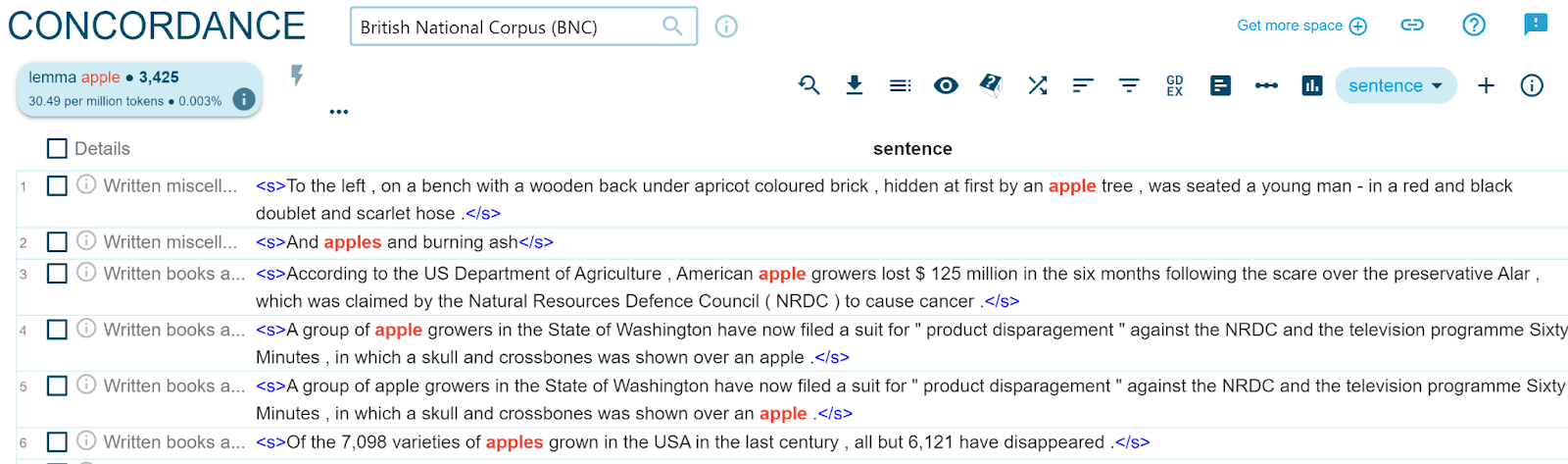
Figure 3. Concordances for apple (sentence view) in the British National Corpus before GDEX sorting
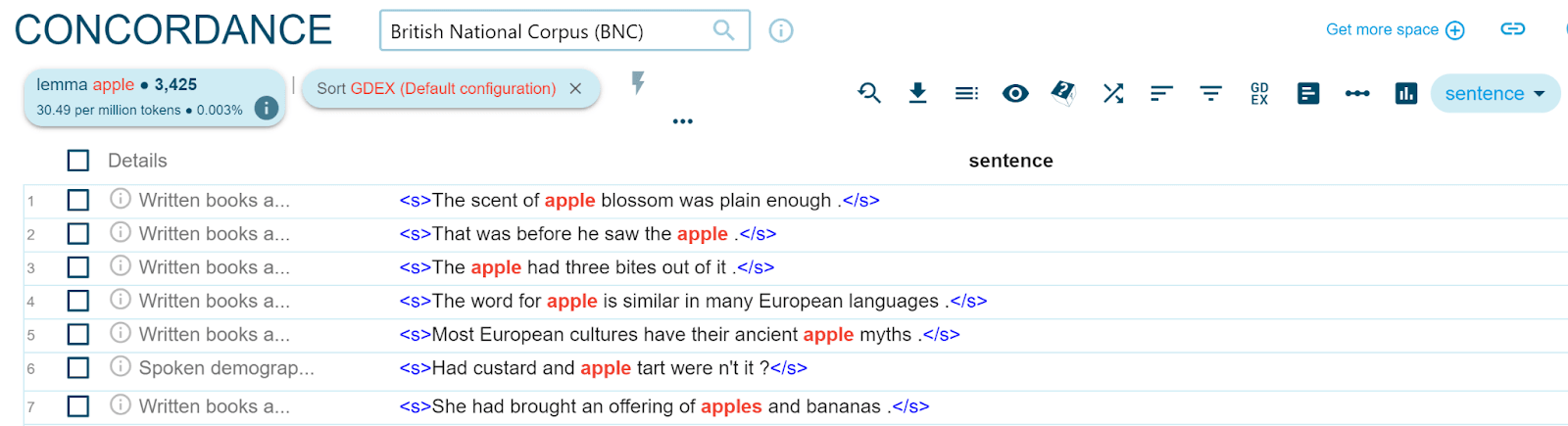
Figure 4. Concordances for apple (sentence view) in the British National Corpus after GDEX sorting
Users of Sketch Engine can use the default configuration, or they can set their own configuration. For more information on how to set a GDEX configuration file in Sketch Engine, see: https://www.sketchengine.eu/syntax-of-gdex-configuration-files/
Tickbox lexicography
TickBox Lexicography (TBL) is a specific feature implemented in Sketch Engine to enable lexicographers a more streamlined way of exporting example sentences related to collocations in the word sketch directly into the DWS. See Kilgarriff et al. (2010) and https://www.sketchengine.eu/user-guide/tickbox-lexicography/
Figure 6. TBL in Sketch Engine
TBL can be customised so that for instance, not only the concordance line is copied, but also the complete sentence together with metadata, is transferred to the clipboard for pasting into the DWS. Being able to quickly copy and paste different types of information from the CQS into the DWS is an essential feature for lexicographers.
Software development in a lexicographic team
Lexicographic tools and software are developed in a team that usually consist of people with quite diverse backgrounds. Setting up an efficient framework for communication and feedback is therefore essential for successful development. We first give an overview of the main roles that are usually present in a lexicographic team. We take the perspective of the Information Systems Development Life Cycle and focus on the phases when communication between team members is most crucial, i.e. the specification of the requirements for lexicographic software systems (CQS, DWS and UI). Next we discuss how the communication process between these roles can be described and formalised to minimise miscommunication using Unified Modeling Language (UML).
Lexicographic institutes and dictionary projects come in different sizes and the number of people involved might differ quite dramatically. In smaller projects, the same person might take different roles. In most projects however, the following roles can be distinguished:
- Dictionary users: Although not formally part of the lexicographic team, dictionary users are the ultimate “customers” and end users for whom an online dictionary is intended. As such, they traditionally set the requirements for the dictionary as a whole, including the content and user interface. However, finding out what exactly (prospective) users need and expect from a dictionary requires an extensive analysis that is typically carried out by a senior lexicographer in cooperation with a data scientist. More recently, there have also been efforts to involve users in the development and creation through crowdsourcing. In that case, the senior lexicographers in charge of the dictionary project will guide the contributors and give them requirements for content creation. More about the role of dictionary users, the analysis of user needs and user involvement can be found in the module Introduction to Dictionary Users.
- Lexicographers: Lexicographers typically have a formal training in (applied) linguistics and usually only a limited background in computer science and software development. Usually a (team of) senior lexicographer(s) is in charge of the dictionary project and they determine the content elements (i.e. the macro- medio- and microstructure) that will be included in the dictionary and that are formalized in a lexicographic data model. As mentioned before, lexicographers get requirements for dictionary content from analysing the needs of dictionary users. Based on the resulting data model, the team’s senior lexicographers will set requirements for the dictionary writing system (DWS) and the dictionary user interface (UI). In corpus-based dictionaries, lexicographers rely on corpus analysis to create dictionary content. Hence, lexicographers in cooperation with computational linguists will also set the requirements for the corpus query system (CQS).
- Computational Linguists: Computational Linguists typically have a mixed background in descriptive (applied) linguistics and computational linguistics. Thanks to this double background, they often mediate in the lexicographic team between on the one hand lexicographers and on the other hand software developers and database architects. Within the lexicographic workflow they are mainly responsible for two computational aspects of the dictionary’s content, viz. knowledge representation and knowledge extraction. With respect to knowledge representation, computational linguists get requirements from the lexicographic data model and they implement this model into a specific data format that supports the intended uses of the dictionary data (see the overview of Standards for Representing Lexicographic Data). Typical data formats are implemented in XML (e.g. TEI Lex-0 or as RDF (e.g. OntoLex-Lemon). Based on the data format for knowledge representation, computational linguists will also set the requirements for the underlying database architecture. With respect to knowledge extraction, computational linguists work with lexicographers to assess for all the content elements to be included in the dictionary which information needs to be extracted from corpora to allow the lexicographers to create this content. Hence computational linguists both set and get requirements for knowledge extraction because they are also responsible for choosing, and partially implementing, the NLP and AI techniques that will be used for lexicographic knowledge extraction from corpora. This, in turn, will set the requirements for the CQS and the underlying text search system that is implemented by software developers.
- Database experts: Database experts get requirements from the data model and the data format to design and implement the databases that store the dictionary content as well as the database management system (DBMS) that will be used for the DWS and the UI.
- Software developers: Software developers are responsible for developing and maintaining the three main software tools used in the lexicographic workflow, viz. CQS, DWS and the UI. Although the requirements for these tools are formulated by the lexicographers and computational linguists, the software developers are often the most limited human resource within the lexicographic team and therefore key in setting scope and time constraints for these tools. Since all three rely on underlying databases, the software developer will set requirements for the database management system.
The difference in technical background within the lexicographic team and, simultaneously, a need for intense cooperation, can pose quite a challenge for effective communication during the specification of requirements. Using a shared, more formal representation of requirements can help to avoid ambiguity and misunderstanding. Within the lexicographic community, Universal Modelling Language (UML) has established itself as a de facto standard for specifying data models of lexicographic content on a conceptual level. Part 2 of the module on Standards for Representing Lexicographic Data illustrates the use of UML diagrams in lexicography, with the UML Class diagram being the most important type of diagram (see this brief online tutorial for an introduction to class diagrams). Although UML is not yet widely used to specify other requirements in lexicography, including tools and databases, software developers and database architects can use UML as a basis to communicate with other members of the lexicographic team in an iterative process of specifying and formalising requirements. Although reports explicitly addressing the design of lexicographic software are scarce, an example of an iterative requirement specification process for a dictionary user interface is described in Nagoya, Liu & Hamada (2015).
Automatic extraction of lexicographically relevant information from corpora
In the course LEX2: Mastering ELEXIS Corpus Tools for Lexicographic Purposes you can learn how you can extract lexicographic information from corpora using Sketch Engine. Here we provide pointers to the relevant literature describing research on automatic information extraction for lexicography. Since this is a rapidly developing field, we advise to use the key concepts and publications mentioned in this section as search terms in google scholar or Elexifinder to find up-to-date publications and resources. For many of the subtasks in automatic information extraction, there are evaluation workshops on a regular basis organised by the Computational Linguistics community to establish the state-of-the-art for a given subtask based on a so-called “shared task” using the same training and test data. The most relevant workshops and shared tasks for lexicographic information extraction are part of the SemEval (Semantic Evaluation) series.
For an introduction to corpora, see section 2 in the course Introduction to Corpus-Based Lexicographic Practice
Automatic extraction of headword lists
A headword list can be obtained in several ways depending on the purpose of the dictionary (see: LEX2: Mastering ELEXIS Corpus Tools for Lexicographic Purposes). For a general-purpose dictionary where the aim is to include all words based on their frequency of use rather than on other qualities, a list of the most common words or lemmas in a corpus sorted by frequency can provide a candidate headword list.
When the aim of the dictionary is to provide information about domain-specific words or specialised terminology, the headword list should be generated by using a keyword and term extraction tool. This also assumes that a specialised domain-specific corpus is used. A keyword and term extraction tool will automatically eliminate general vocabulary and will only return words which are specific to the corpus, typically nouns, adjectives and noun phrases. In his 2009 paper, Adam Kilgarriff describes a simple algorithm for identifying single keywords in one corpus versus a reference corpus and this is also used in the SketchEngine. More complex algorithms for extraction of both single and multiword terms have been developed in the NLP domain of Automatic Term Extraction. See Heylen & De Hertog (2015) for an introduction and Rigouts Terryn, Hoste & Lefever (2022) for a recent overview. The TermEval 2020 worskhop benchmarked systems for monolingual term extraction.
Automatic extraction of collocations and word sketches
In corpus linguistics, a collocation is a series of words that co-occur more often than statistically would be expected by chance. The set of collocations in which a specific word occurs can give lexicographers insight into the meanings of that word. Automatic collocation extraction is an extensive field of research that investigates the statistical measures and constraints on co-occurrence relations for the identification of different types of collocations (See Evert 2009 for a first introduction). In lexicography, collocations constrained by specific syntactic relations are used to generate lexical profiles in a CQS, with the Word Sketches in SketchEngine as the best known implementation (see Kilgarriff &Tugwell 2001 for the original paper). Whereas Word Sketches approximate syntactic relations through Part-of-Speech patterns (so-called Sketch Grammars), more recent approaches rely on dependency parsed corpora to generate lexical profiles (see Garcia et al. 2019 for an overview).
Automatic extraction of good dictionary examples
A good starting point for learning more about identifying and extracting good dictionary examples is the article by Kosem et al. (2019). This work adopts a rule-based approach. Machine learning approaches are also used. See, for instance, Lemnitzer et al. (2015) who use a combination of a machine learning and rule-based approach, Ljubesic and Peronja (2015) who use supervised machine learning to predict the quality of corpus examples, and Khan et al. (2021) who experimented with deep learning techniques. Related work on the extraction of example sentences from corpora can also be found in the field of language learning (e.g. Pilán et al. 2014).
Automatic Word Sense Induction/Disambiguation
Word Sense Induction (WSI) and Word Sense Disambiguation (WSD) are two related tasks that are central to the lexicographic enterprise, viz. identifying the different meanings of a word. Whereas WSI tries to identify word meanings from corpus data in an unsupervised bottom-up way, WSD starts from an existing sense inventory and tries to assign the correct sense to each occurrence of a word. An overview of approaches can be found in Camacho-Collados & Pilehvar (2018). For work on Word Sense Disambiguation that has been carried in the ELEXIS project, see the deliverables D3.2 Multilingual Word Sense Disambiguation and Entity Linking algorithms – initial report and D3.5 Multilingual Word Sense Disambiguation and Entity Linking - Final Report, as well as relevant publications in ELEXIS community on Zenodo. There have been different SemEval shared tasks on WSI and WSD and an overview of the currently best performing systems is available on the NLP-progress website.
Automatic extraction and generation of definitions
A current research topic in computational lexicography is the automatic creation of word definitions for dictionary entries. Within ELEXIS, this research has been pursued under the heading of the OneClick Dictionary (see the module on Automating the Process of Dictionary Creation). The research in Computational Linguistics more widely can be subsumed under two approaches. The automatic extraction of definitions tries to find definitions or definition-like contexts in large text corpora. Espinosa-Anke et al. (2015) presented a weakly supervised system for the extraction of dictionary definitions from general text and Spala et al.(2020) introduced a shared task for definition extraction from domain specific text. An alternative approach tries to generate definitions based on semantic vector representations (embeddings). Noraset et al. (2017) introduced the task of definition modelling and Bevilacqua et al. (2020) present the Generationary system to generate short definitions known as glosses.
Automatic extraction of thesaurus items
Thesauri contain relations between words on the sense level. These include synonymy relations but also type-of relations (hyponymy) or part-whole relations (meronymy). Most approaches for the automatic extraction of synonyms and other related words rely on vector representations of word meaning, a.k.a. word embeddings. A general introduction to vector representations can be found in chapter 6 of Juraksy & Martin’s online textbook on speech and language processing. An implementation in a CQS is described on the SketchEngine blog.
Automatic extraction of neologisms and novel senses
Neologisms are new words that enter the language. Automatic neologism extraction tries to identify those new words in continuously updated corpora (so-called monitor corpora) and then tracks the popularity of these new words. This then allows lexicographers to assess whether the neologisms merit inclusion in the dictionary. Kerremans et al (2018) and Kosem et al. (2021) both present their own neologism extraction and tracking system but also give an overview of the field. Related to this is the automatic identification of novel senses of existing words. Schlechtweg et al. (2020) introduced a SemEval task for unsupervised lexical semantic change detection in corpora and also give an overview of previous work that relies on semantic vector representations. Nimb et al. (2020) take an explicitly lexicographic perspective and use a simpler bi-gram approach to identify missing dictionary senses in corpora. Cartier (2017) presents the open-source platform neoveille.org for finding and monitoring both new words and new meanings in monitor corpora.
Pointers to other resources
Elexifinder
If you are looking for publications on a particular lexicographic topic, try Elexifinder. Elexifinder is a tool which has been developed within the ELEXIS project in order to facilitate knowledge exchange in the lexicographic community and promote open access culture in lexicographic research. It is the most up to date tool for finding publications on lexicographic research.
Language Resources and Tools
CLARIN
CLARIN stands for Common Language Resources and Technology Infrastructure and is a distributed digital infrastructure with participating institutes from all over Europe that offers data, tools and services to support language-related research and development. The main parts are:
- The Virtual Language Observartory is CLARIN’s unified catalogue of resources.
- The Switchboard has online NLP tools for text processing.
- CLARIN Knowledge-Centres that offer expertise on specific topics. An ELEXIS - CLARIN Knowledge Centre for Lexicography will come online in autumn 2022.
A separate module of the ELEXIS Curriculum gives an overview of the CLARIN Tools and Resources for Lexicographic Work.
European Language Grid
The European Language Grid provides access to Language Technology resources from all over Europe. ELG contains tools and services, language resources and information on European LT companies and research organisations as well as their projects.
Other websites with overviews of corpus resources
- https://corpus.tools/ A joint portal of the Masaryk University’s NLP Centre and Lexical Computing dedicated to a number of software tools for corpus processing.
- https://corpus-analysis.com/ A comprehensive list of tools used in corpus compilation and analysis which is kept up to date by users.
- Essex university W3 Corpora project
Mailing lists and special interest groups
Corpora mailing list
A mailing list for questions related to corpora. Information page: https://list.elra.info/mailman3/postorius/lists/corpora.list.elra.info/
ACL
The Association for Computational Linguistics. It provides a good starting point for exploring the field of computational linguistics. Within ACL, there are a number of special interest groups, e.g. a special interest group on the lexicon (SIGLEX), and special interest group on computational semantics (SIGSEM).
Linked (Open) Data for lexicography
For an introduction to Linked Data for Linguistics, see the material from EUROLAN2021 training school which was organised with the support of the NexusLinguarum COST action. All presentations (slides) and exercises accompanied by code and data examples of the training school have been published online and are made freely available. The presentation of the lexicog module by Julia Bosque-Gil is particularly relevant in the context of lexicography.
Bibliography
Abel, A. (2012). Dictionary writing systems and beyond. In: Granger, Sylviane / Paquot, Magali (eds.): Electronic Lexicography. Oxford: Oxford University Press. https://www.researchgate.net/publication/259453133_Dictionary_Writing_Systems_and_Beyond
Bevilacqua, M., M. Maru, and R. Navigli. (2020). Generationary or: “How We Went beyond Sense Inventories and Learned to Gloss”. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP).
Camacho-Collados, J., and Pilehvar, M. T. (2018). From word to sense embeddings: A survey on vector representations of meaning. Journal of Artificial Intelligence Research, 63, 743-788.
Cartier, E. (2017). ‘Neoveille, a web platform for neologism tracking’, in Proceedings of the Software Demonstrations of the 15th Conference of the European Chapter of the Association for Computational Linguistics, 95–98.
Espinosa-Anke, L., Ronzano, F. and Saggion, H. (2015). ‘Weakly supervised definition extraction’, in Angelova G, Bontcheva K, Mitkov R, editors. International Conference on Recent Advances in Natural Language Processing 2015 (RANLP 2015); 176-85.
Evert, S. (2009). “Corpora and collocations”. Volume 2: An International Handbook, edited by Anke Lüdeling and Merja Kytö, Berlin, New York: De Gruyter Mouton, 2009, 1212-1248. https://doi.org/10.1515/9783110213881.2.1212
Garcia, M., Salido, M.G. and Ramos, M.A. (2019). ‘A comparison of statistical association measures for identifying dependency-based collocations in various languages.’, in Proceedings of the Joint Workshop on Multiword Expressions and WordNet (MWE-WN 2019), 49–59.
Herman, O. et al. (2019). ‘Word Sense Induction Using Word Sketches’, in C. Martín-Vide, M. Purver, and S. Pollak (eds) Statistical Language and Speech Processing. Cham: Springer International Publishing (Lecture Notes in Computer Science), 83–91. Available at: https://doi.org/10.1007/978-3-030-31372-2_7.
Heylen, K. and De Hertog, D. (2015). ‘Automatic Term Extraction’, in H. Kockaert and F. Steurs (eds) Handbook of Terminology. Volume 1. Amsterdam: John Benjamins Publishing Company, 203–221.
Jurafsky, D. and Martin, J.H. (3rd draft) (2018). Speech and language processing.
Kallas, J., Koeva, S., Kosem, I., Langemets, M. and Tiberius, C. (2019a). ELEXIS deliverable 1.1 Lexicographic Practices in Europe: A Survey of User Needs..
Kerremans, D. and Prokić, J. (2018). “Mining the web for new words: Semi-automatic neologism identification with the NeoCrawler.” Anglia 136.2: 239-268.
Khan, M. Y., Qayoom, A., Nizami, M. S., Siddiqui, M. S., Wasi, S. and Raazi, S. M. K. U. R. (2021). Automated Prediction of Good Dictionary EXamples (GDEX): A Comprehensive Experiment with Distant Supervision, Machine Learning, and Word Embedding-Based Deep Learning Techniques. Complexity, 2021.
Kilgarriff, A. and Tugwell, D. (2001). “Word sketch: Extraction and display of significant collocations for lexicography.” in Proceedings of the Collocations workshop, ACL 2001,Toulouse,France: 32-38.
Kilgarriff, A., Kovár, V. and Rychly, P. (2010). ‘Tickbox Lexicography’ In Granger, S. and M. Paquot (eds), eLexicography in the 21 st Century: New Challenges, New Applications. Proceedings of eLex 2009. Louvain-la-Neuve: Presses Universitaires de Louvain, 411–418.
Klosa-Kückelhaus, A., and Michaelis, F.. (2022) “The design of internet dictionaries.” The Bloomsbury Handbook of Lexicography: 405.
Kosem, I. (2016). Interrogating a Corpus. In Philip Durkin (ed.) The Oxford Handbook of Lexicography.
Kosem, I., et al. “Language Monitor: tracking the use of words in contemporary Slovene.” Electronic lexicography in the 21st century (eLex 2021) Post-editing lexicography: 93.
Kosem I., Koppel, K., Zingano Kuhn, T., Michelfeit, J., Tiberius, C. (2019). Identification and automatic extraction of good dictionary examples: the case(s) of GDEX, International Journal of Lexicography, Volume 32, Issue 2, June 2019, 119–137, https://doi.org/10.1093/ijl/ecy014
Lemnitzer, L., C. Pölitz, J. Didakowski and Geyken, A. (2015). ‘Combining a Rule-based Approach and Machine Learning in a Good-example Extraction Task for the Purpose of Lexicographic Work on Contemporary Standard German’ In Kosem, I., M. Jakubicek, J. Kallas and S. Krek (eds), Electronic Lexicography in the 21st Century: Linking Lexical Data in the Digital Age. Proceedings of the eLex 2015 Conference, 11-13 August 2015, Herstmonceux Castle, United Kingdom. Ljubljana/Brighton: Trojina, Institute for Applied Slovene Studies/Lexical Computing Ltd., 21–31.
Ljubesic, N. and Peronja, M. (2015). ‘Predicting Corpus Example Quality via Supervised Machine Learning’ In Kosem, I., M. Jakubicek, J. Kallas and S. Krek (eds), Electronic Lexicography in the 21st Century: Linking Lexical Data in the Digital Age. Proceedings of the eLex 2015 Conference, 11-13 August 2015, Herstmonceux Castle, United Kingdom. Ljubljana/Brighton: Trojina, Institute for Applied Slovene Studies/Lexical Computing Ltd., 477–485.
Nagoya F., S. Liu and Hamada, K. (2015).. “Developing a Web Dictionary System Using the SOFL Three-Step Specification Approach,” In: 5th International Conference on IT Convergence and Security (ICITCS), 2015, 1-5, doi: 10.1109/ICITCS.2015.7292971.
Nimb, S., Sørensen, N.H. and Lorentzen, H. (2020). ‘Updating the dictionary: Semantic change identification based on change in bigrams over time’, Slovenščina 2.0: empirical, applied and interdisciplinary research, 8(2), 112–138.
Noraset, T. et al. (2017). ‘Definition modeling: Learning to define word embeddings in natural language’, in Thirty-First AAAI Conference on Artificial Intelligence.
Pilán, I., E. Volodina and Johansson, R. (2014). ‘Rule-based and Machine Learning Approaches for Second Language Sentence-level Readability’. In Proceedings of the Ninth Workshop on Innovative Use of NLP for Building Educational Applications, 174–184.
Schlechtweg, D. et al. (2020). ‘SemEval-2020 Task 1: Unsupervised Lexical Semantic Change Detection’, in Proceedings of the Fourteenth Workshop on Semantic Evaluation. Barcelona (online): International Committee for Computational Linguistics, 1–23.
Spala, S., Miller, N., Dernoncourt, F. and Dockhorn, C. (2020). SemEval-2020 Task 6: Definition Extraction from Free Text with the DEFT Corpus. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, 336–345, Barcelona (online). International Committee for Computational Linguistics.
Terryn Rigouts, A., Hoste, V. and Lefever, E. (2022). ‘Tagging terms in text: A supervised sequential labelling approach to automatic term extraction’, Terminology. International Journal of Theoretical and Applied Issues in Specialized Communication, 28(1), 157–189.