CLARIN Tools and Resources for Lexicographic Work
This course introduces lexicographers to the CLARIN Research Infrastructure and highlights language resources and tools useful for lexicographic practices. The course consists of two parts. In Part 1, you will learn about CLARIN, its technical and knowledge infrastructure, and about how to deposit and find lexical resources in CLARIN. In Part 2, you will become acquainted with CLARIN tools that can be used to create lexical resources.
Target audience
Linguists, professional lexicographers, students and graduates in related disciplines, lecturers teaching lexicography.
Learning Outcomes
Upon completion of this course, students will be able to
- appreciate importance of FAIR and Open data and the role of research infrastructures to ensure that lexical data is correctly preserved
- deposit their lexical resource on a CLARIN DSPACE type of repository (such as ILC4CLARIN), with the appropriate metadata, understand the versioning of resources, cite their resource appropriately
- search for and locate existing lexical resource within the CLARIN infrastructure (VLO, Resource Families)
- create a simple lexical resource by means of LexO, a collaborative editor of OntoLex-Lemon resources
- build a simple lexical resource (in TEI) with the <TEI>enricher
Prerequisites
This course requires basic knowledge of Lexicography, which can be acquired from the Introduction to Dictionaries and the Introduction to Corpus-Based Lexicographic Practice courses. In addition to this, we recommend doing the course Modeling Dictionaries in OntoLex-Lemon before starting Part 2 of this course. If you are interested in learning more about the topics of Part 1 of this course, we suggest continuing with Lexicography in the Age of Open Data and Standards for Representing Lexical Data: An Overview.
The CLARIN infrastructure
What is CLARIN
CLARIN stands for “Common Language Resources and Technology Infrastructure”. It is a research infrastructure that embodies the long-term vision of making the language resources and tools from all over Europe accessible online. It is organised as a distributed network of centres, offering resources, services and domain specific knowledge.
Currently, CLARIN provides easy and sustainable access to digital language data (in written, spoken, or multimodal form) for scholars in the social sciences and humanities, and beyond. CLARIN also offers advanced tools to discover, explore, exploit, annotate, analyse or combine such data sets. CLARIN provides several services, such as access to language data and tools to analyze data, and offers a research data depositing service, as well as direct access to knowledge about relevant topics related to (research on and with) language resources.
Exercises:
- To learn more, see the CLARIN website, and in particular the About section.
- For a short intro, see CLARIN 101 - a 3 minutes intro into CLARIN
From the legal point of view, CLARIN is an ERIC, a European Research Infrastructure Consortium. Member countries contribute to the ERIC financially and in kind, for instance by hosting one of the over 60 CLARIN centres.
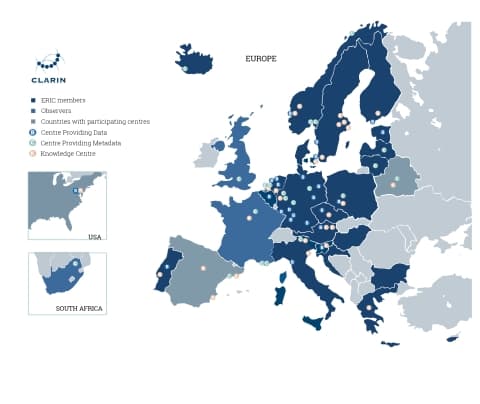
See also this Overview of CLARIN Centers
Researchers from member countries have access to a number of services and opportunities, which will be explored in this course.
Exercise:
- Search the CLARIN portal to find out whether your country is part of CLARIN, who is the National Coordinator, whether there are CLARIN centres near you.
Technical Infrastructure
Before beginning, please watch the following video:
CLARIN is organised as a networked federation of centres located in various countries: language data repositories, service centres and knowledge centres, with single sign-on access for all members of the academic community in all participating countries.
Tools and data from different centres are interoperable, so that data collections can be combined and tools from different sources can be chained to perform complex operations to support researchers in their work.
Interoperability is achieved by central services, accessible from the CLARIN portal, which allow one to discover and use resources made available and hosted by the various centres.
The Virtual Language Observatory - VLO provides a means of exploring language resources and tools. Its aim is to provide an easy to use interface, allowing for a uniform search and discovery process for a large number of resources from a wide variety of domains. Facets make it easy to explore and access available resources.
The VLO searches for metadata only. To enable researchers to search for specific patterns across collections of data, CLARIN developed Content Search, a search engine that connects to the local data collections that are available in the centres. The data itself stays at the centre where it is hosted – therefore the underlying technique is called federated content search. The search engine summarizes and displays what is available. An easy next step is to go to the centre’s specialised search interface to perform a more sophisticated query.
Finally, the Language Resource Switchboard is a tool that helps you to find a matching language processing web application for your data. After uploading a file or entering a URL, you can select which task to perform. The Switchboard will then provide you with a list of available CLARIN tools to analyze the input. Crucially, the Switchboard can also be activated from data found from the VLO.
Exercises:
- Explore the VLO (later we will see how to search for lexical resources in the VLO) and the Content Search
- Try to upload a short text in your language on to the Switchboard, to see what resources are available
Knowledge Infrastructure
The mission of the CLARIN Knowledge Infrastructure (KI) is to ensure that the knowledge and expertise available within CLARIN do not exist as a fragmented collection of unconnected bits and pieces, but are made accessible in an organized way to the CLARIN community and to the Social Sciences and Humanities research community at large. We will not go into the details of the CLARIN Knowledge Infrastructure. For more information see the relevant section of the CLARIN portal, but just provide the elements that are more relevant for the purposes of this course.
CLARIN Knowledge Centres (abbreviated K-centres) are a cornerstone of the CLARIN knowledge infrastructure. K-centres are institutions that have agreed to share their knowledge and expertise on one or more aspects of the domain covered by the CLARIN infrastructure. They all have a helpdesk that will respond to requests within 2 working days. Some offer on-line courses, some offer best-practice documents, some offer guidance in getting access to and using data and tools, some are willing to host receivers of CLARIN mobility grants, and there are many more models in which the expertise is offered and shared.
Another important source of information on Language Resources is the Resource Families initiative. The aim of the CLARIN Resource Families initiative is to provide a user-friendly overview per data type of the available language resources in the CLARIN infrastructure aimed at the needs of researchers from digital humanities, social sciences and human language technologies. The overviews are meant to facilitate comparative research and the listings are sorted by language.
In addition, CLARIN offers an extensive collection of Video Lectures.
Other useful CLARIN initiatives are:
- The Digital Humanities Course Registry is a curated platform that provides an overview of the growing range of teaching activities in the field of digital humanities worldwide. It is maintained as a joint effort of two European research infrastructures: CLARIN-ERIC and DARIAH-EU.
- The Standard Committee (SC) and a Committee for Legal and Ethical Issues (CLIC), which provide advice and guidance in their respective areas of competence.
Finally CLARIN has developed a number of funding and support instruments which are meant to address strategic priorities that require cross-country collaboration, exchange of expertise, training or mobility.
If you have a new project, and are looking for information and expertise on a specific topic remember that all researchers from CLARIN member and observer countries can:
- contact a K-centre to ask for relevant information
- apply for a mobility grant to visit a centre
- avail themselves of other support instruments, for instance to organise events
- get in touch with the SC and CLIC representatives for information on standards and legal issues - notice that members of the CLARIN standard committee have been involved in the ELEXIS project and have extensive expertise on lexical resources.
- finally, get in touch with your CLARIN National Coordinator and national centres
Use the CLARIN KI to find useful information for your lexicography project or training
Exercises
- Use the keyword based search to find information on K-centres with expertise in your area
- Search for online courses from your country in the DH course registry
CLARIN and FAIR, Open Data
The FAIR data principles state that language resources, like all research data, have to be Findable, Accessible, Interoperable, Reusable. Even though CLARIN has been in existence for a longer period than the FAIR data principles themselves, the core values of CLARIN – facilitating the reuse of language data and tools for research – align very closely with FAIR. CLARIN was a FAIR case ‘avant la lettre’.
Exercise:
- Read on the CLARIN portal how the CLARIN services can help you make your Lexical resources and other Language Resources FAIR
In particular, CLARIN deposit services are crucial to adhere to good principles of Open Science.
- Many CLARIN centres are certified, thus ensuring long term preservation of data and the adherence to shared data curation practices
- The CLARIN Service Provider Federation allows users to access protected data stored on a CLARIN centre with Single Sign On, that is with your institutional login
- Moreover, CLARIN centres will advise you on the best choice of license for your data, to ensure maximum visibility and will help you to make your data as open as possible.
Remember, while institutional repositories can be very useful to keep all of your scientific production in one place, depositing in disciplinary repositories such as clarin centres is recommended to ensure the visibility of your data to the most relevant communities. In the case of CLARIN, the visibility to the broader DH community is ensured by the VLO.
Finally, the adherence to Open Science principles is now more and more a requirement for funded projects, especially at the European Level. A Data Management Plan (DMP), that is to say a document that specifies how research data will be collected, processed, monitored and catalogued during the project lifetime - is required for Horizon Europe projects too.
Exercises:
- Read on the CLARIN portal how CLARIN can help you with your project and DMP
- Learn more about FAIR data and Open Science in the course “Lexicography in the Age of Open Data” TODO: ADD LINK (Toma)
Searching for resources and information in the CLARIN infrastructure
We have seen that the CLARIN VLO is a sort of meta catalogue that gives access to all resources from the various centres. Metadata from repositories in the CLARIN network are harvested on a weekly basis, so when a new resource is deposited in one of them, it will become almost immediately visible from the VLO. Note that different centres use different but interoperable metadata profiles.
- You can find out more about metadata and CLARIN on the website.
Let us see now how to make a search on the VLO, and more specifically how to find how many digitised dictionaries are present and in which languages and formats:
- First of all, go to the VLO home page and click on the button “Take a quick tour”. You will be guided through all of the main search functions
- Then go back to the home page, click “See all records” to activate the faceted search
- First run a free text query for “French dictionary”, you can see that results are not very precise. Sometimes you obtain bilingual resources or even resources that are not in French
- With a faceted search you can be more precise. Try first to select ResourceType = Dictionary. Only a few resources appear. Why? Because many of the resources from the previous search are not classified as “Dictionary”, but as “Lexical Resources”. Now try ResourceType = lexicalResource.
- You can combine various resource types in one query. Such as ResourceType = lexicalResource+LexicalResource+Dictionary
- However, the concept of Lexical Resource is broader than that of Dictionary, so your search will yield resources such as worlists, WordNets, etc. Try to add the free text search now, to filter only those resources that are called “Dictionary”
- You can now use the Language facet to explore all the languages for which a dictionary is present in CLARIN
- Select for instance the Concise Dictionary of Latvian, access the resource or go to the landing page on the Lindat repository; you can see that in this case the record does not contain a downloadable file. The resource can only be accessed online
- Select now the LMF Contemporary Arabic dictionary, also hosted by Lindat. By accessing the landing page, you will find the downloadable file at the bottom of the record. As stated in the description, the format is XML, following the LMF standard
Explore further:
- Check how many other resources are available in XML format
- Which language has more dictionaries in the VLO after English? Where do these resources come from? Use the button “Show more facets” to explore different values of the “Data Provider” facet
Corpora and concordancers can also be useful resources for lexicographers. The VLO allows you to search for this type of resource too. You can follow a similar strategy as the one described above. Searching for Finnish corpora you will find for instance the “Corpus of Finnish Magazines and Newspapers from the 1990s and 2000s, Version 2”, which is made available by Fin-CLARIN via the Korp interface.
- Explore the aforementioned corpus and many others from Korp
- A lot more concordancers are available within CLARIN, and many of them are accessible from the Content Search. Explore the collocations of “affaire/Affaire” in German and French corpora.
As these exercises have shown us, the VLO gives access to a large number of resources. Faceted searches allow expert users to refine their criteria and run very specific queries. It may be a bit difficult to get a quick overview of a given type of resource. For this reason, the Resource Families project was launched. It collects resources from CLARIN centres and also other relevant resources by type; additional metadata are added and the resulting lists are collected in easy to explore pre-compiled lists.
Currently overviews are available of 12 corpora families, 5 families of lexical resources, and 4 tool families.
- Check the Resource Family “Dictionaries”. Do you find all the resources that were retrieved from the previous VLO queries?
- Which dictionaries can be accessed online and which also downloaded?
- Some resources are integrated in fully fledged lexicographic environments. Explore for instance the Digital Dictionary of the German Language (DWDS)‘s web page.
The CLARIN knowledge infrastructure also contains useful information on lexicographic tools and resources.
- You can use the K-centres search function and type in “Dictionaries”, to find all the k-centres with lexicographic expertise
Finally, you can also explore the Tour De CLARIN, an initiative that aims to periodically highlight prominent resources, tools, research outcomes, events from a particular CLARIN national consortium or centre.
- Open the pdf for volume 1 and search for “Dictionaries”. What do you find?
- What is the “Viennese Lexicographic Editor” ?
Depositing Services
As we have seen, in order to fully adhere to the principles of Open Science, your data must be deposited in a certified repository. To help researchers to store their resources (e.g. corpora, lexica, audio and video recordings, annotations, grammars, etc.) in a sustainable way, many of the CLARIN centres offer a depositing service. They are willing to store the resources in their repository and assist with the technical and organisational details. This has a wide range of advantages:
- Long-term archiving: a storage guarantee can be given for a long period (up to 50 years in some cases)
- Resources can be cited easily with a persistent identifier (PID)
- The resources and their metadata will be integrated into the infrastructure, making it possible to search them efficiently.
- Password-protected resources can be made available via institutional login.
- Once resources are integrated in the CLARIN infrastructure, they can be analyzed and enriched more easily with various linguistic tools (e.g. automated part-of-speech tagging, phonetic alignment or audio/video analysis).
Here is what you have to do to deposit your lexical resource on a CLARIN repository. This step-by-step guide is imagined for a small project. For larger projects please contact the CLARIN centre beforehand.
Find your repository from the list of certified CLARIN depositing services.
Check on the repository’s web page whether you have the right to deposit and what are the resources. For instance, the CLARIN Slovenia repository (CLARIN.SI) contains a statement with the conditions and terms of use. It also contains an explanation of why the CLARIN.SI repository is a good choice.
Is the data in the right format? Your lexical resource should be deposited in a standard format (TODO link with “Standards for Representing Lexical Data: An Overview”), and provided with the correct documentation. Some repositories only accept some types of language resources, or some standards. For instance the French CLARIN centre Ortolang recommends XML, TEI, LMF, MAF and SYNAF.
Choice of license. CLARIN repositories can provide help in the choice of the license; they will respect your choice of license but will encourage you to choose an open one if possible. You can also use the CLARIN license calculator.
How to deposit. Various CLARIN repositories use different software, for this reason there is not a single guide to depositing data. However, many CLARIN centres use CLARIN DSpace. Depositing in any such centre is very easy to do.
- Read the excellent deposit tutorial on the CLARIN Slovenia repository; other centres using CLARIN dspace have similar pages (see the Italian one)
- Explore the way in which various types of lexical resources are deposited and described on the ILC4CLARIN repository
Once the lexical resource is deposited on the repository, it will become searchable via the VLO as well, usually in a few days.
Citation: you should note down the PID (CLARIN uses handles) that your resource has been assigned, and use it to cite the resource in your papers, CV, and professional website. You should encourage others to use the preferred citation form including the PID. By doing so, you can track citations of your data, for instance by searching on Google Scholar.
- Check the citations of resources from the Lithuanian repository, by running a Google Scholar query on the repository’s prefix.
- To know more about this topic, watch the recordings of the SSHOC Workshop: Data Citation in Practice. You will also learn about another very useful CLARIN service, the Virtual Collections Registry.
Versioning: check what is the versioning policy of the repository. CLARIN repositories normally operate on a strict versioning policy. Every time you change your data a new version should be submitted, no matter how small the change. Old versions continue to exist, but point to new ones.
-
Check this resource on the Lindat CLARIN repository, which is currently replaced by a more recent one, as the page shows.
Hajič, Jan and Hlaváčová, Jaroslava, 2016, MorfFlex CZ 161115, LINDAT/CLARIAH-CZ digital library at the Institute of Formal and Applied Linguistics (ÚFAL), Faculty of Mathematics and Physics, Charles University, http://hdl.handle.net/11234/1-1834.
Remember. Data can be available in various formats. It is important to learn to distinguish between the information contained in a given lexical resource, and the various formats and modes it is accessible in.
- Consider the Resource “Italwordnet”. See in the VLO how it is available in various formats (query here). Then check out the online browsing interface.
Only when a lexical resource is downloadable in its source format, so that the user can perform any query on it, can it be considered fully open.
Using CLARIN Tools for lexicography
LexO-lite: what is and who is it for
LexO-lite (simply LexO from now on) is a collaborative web editor for easily building and managing lexical and terminological resources in the context of the Semantic Web. The adoption of Semantic Web technologies and the Linked Data paradigm is driven by the need to ensure the construction of resources that are interoperable, shareable and reusable by the scientific community. LexO’s primary objective is to enable lexicographers, scholars and humanists to create a resource ex novo where information can be easily manually curated by humans, that is fundamental for collecting reliable, fine-grained, and explicit information. LexO attempts to make the OntoLex-Lemon model accessible to all those who do not have technical skills, allowing for the adoption of new technological advance in the Semantic Web by Digital Humanities. The tool allows for information to be easily manually curated by humans. LexO is a free and open source project and its source code can be downloaded from here.
Installation
Users can compile and install LexO on their own machine, by following the instructions reported in here. This implies you will run the most recent version of the LexO code, which will not necessarily be a stable version.
Current limitations
LexO is not a funded project. From the technological point of view, it is based on an open source Java library called OWL-API. However, a solution that implements a persistence strategy based on triple stores is more indicated for medium/large-sized data. For this reason, we called this tool version LexO-lite. The suffix lite refers to the limited ability to manage small-sized lexica, typically domain terminologies and specialized lexica. A full version of LexO that will be capable of managing large-scale resources in currently in progress. Please notify bugs or issues on the project github page.
Tool description
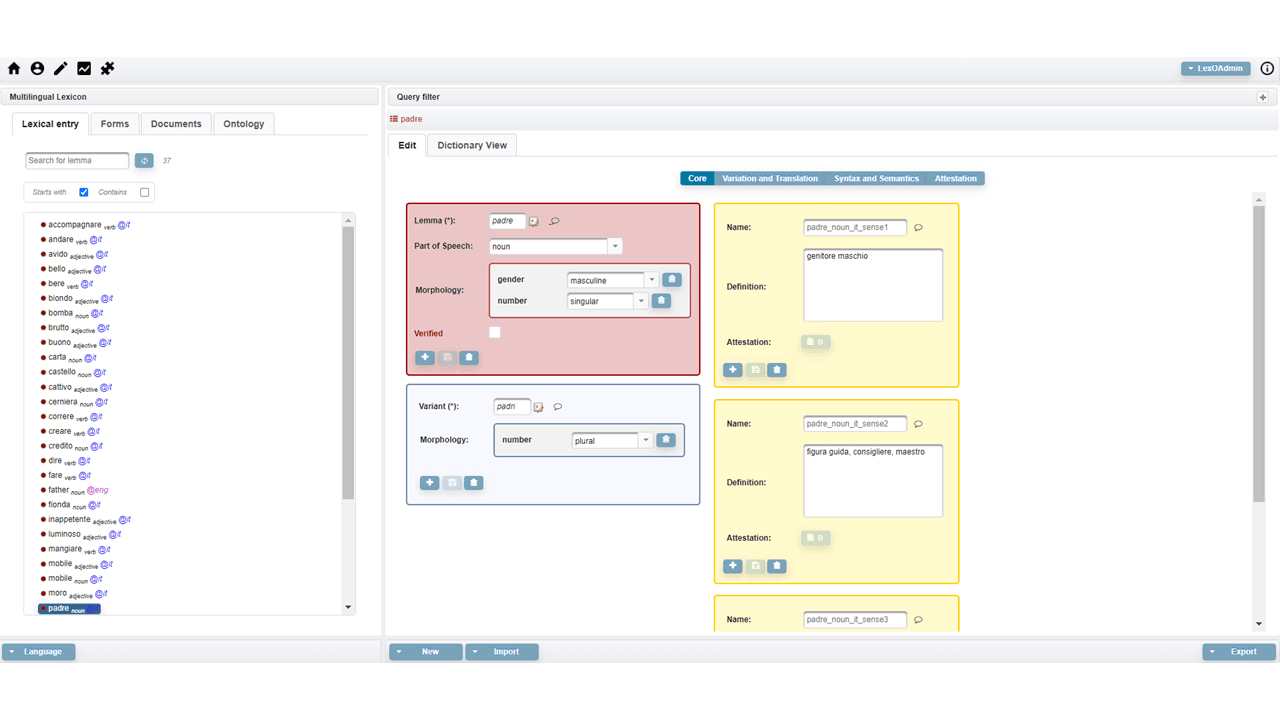
The main interface of LexO is depicted in the following figure.
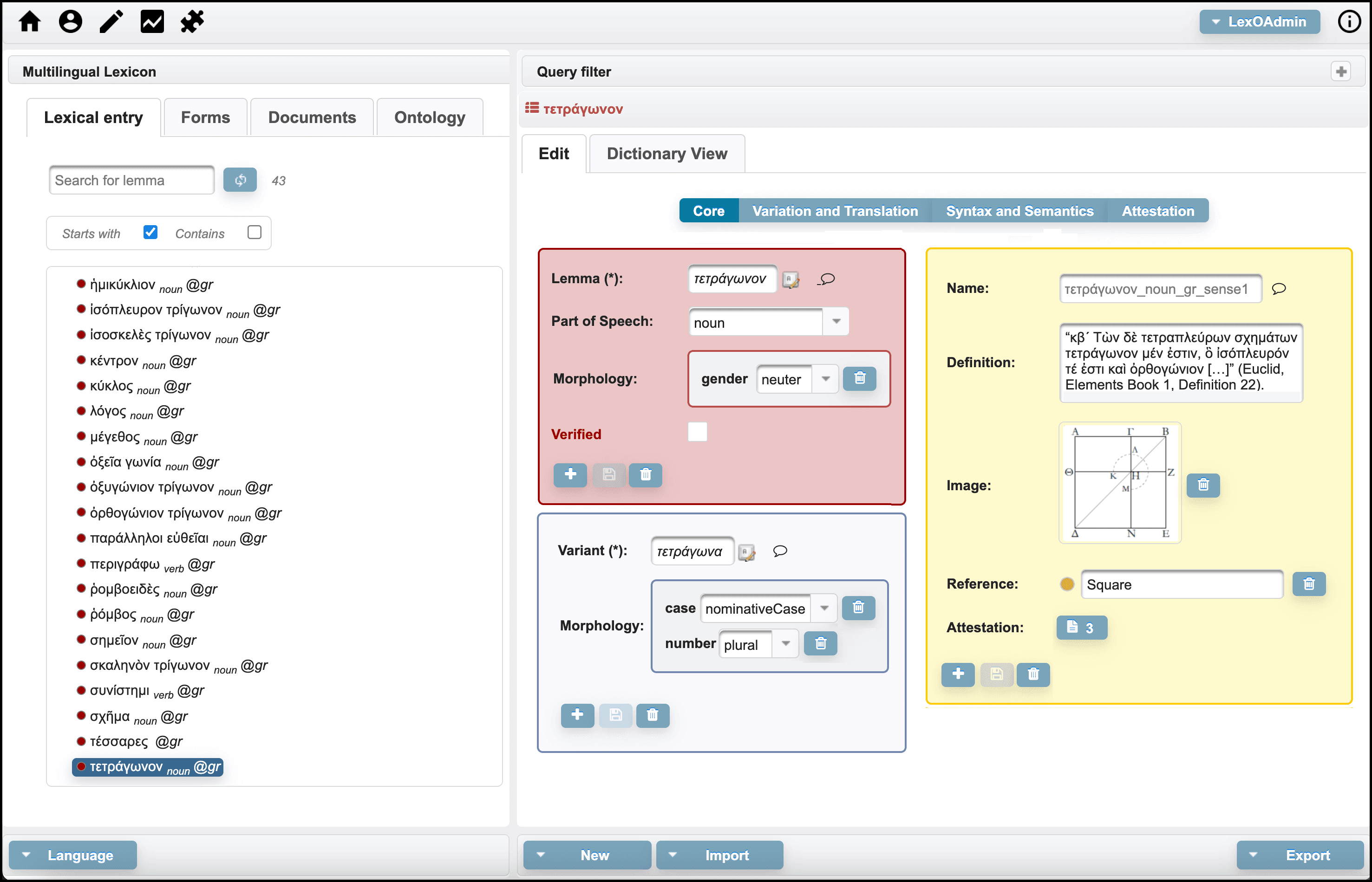
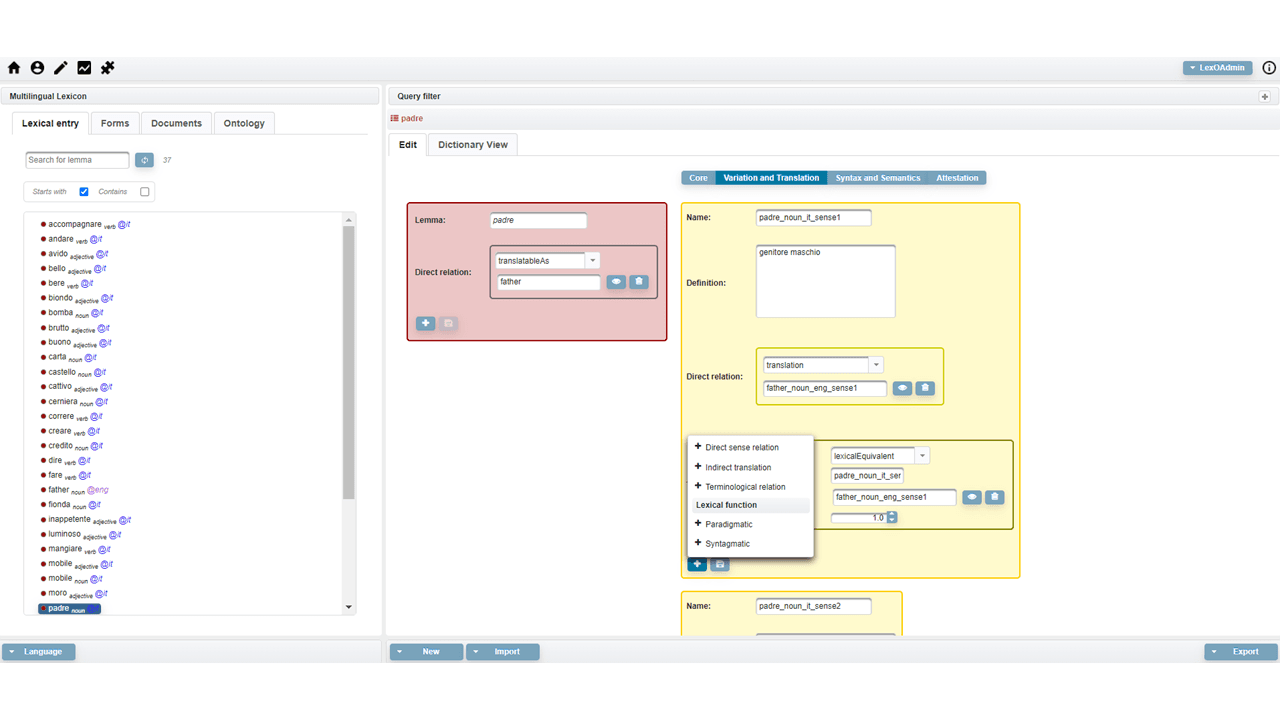
The leftmost column contains four tabs and a browsing component with a simple search box where the list of the elements contained in the selected tab is displayed. Specifically, by clicking on the first tab, users can view all the lexical entries of the dictionary, represented by their canonical written form and accompanied by information about the part-of-speech and the language. The second tab provides all the inflected forms listed in alphabetical order. In the case of multilingual resources, lemmas and forms can be filtered by language. The Documentation tab is dedicated to enumerating the texts of the corpus from which terminology is extracted. Finally, the Ontology tab contains the conceptual part of the lexicon. All the information relating to the element selected in the browsing component is visualised in the rightmost column.
The figure above shows the information displayed when selecting the greek lexical entry τετράγωνον (‘square’ in English): in the red box the main information concerning the lemma, such as grammatical category, gender and number are illustrated; in the blue box you will find the description of the forms occurring in the reference text. The senses are described in the yellow boxes. As far as the Documentation tab is concerned, LexO shows the metadata panel of the selected text; the Ontology tab instead lists the concepts belonging to a reference ontology that would have been previously uploaded.
Since LexO allows users to create resources in a collaborative way, it defines three kinds of user profiles i.e., administrator (edit rights and users management), user (edit rights), viewer (browsing only). The system allows administrators to validate a lexical entry by means of the “verified” checkbox in the lemma box, in such a way that it can no longer be modified by users that are not administrators. This functionality makes it possible to implement a sort of revision process, for the final export of the resource in the OntoLex-Lemon model, which can be done by means of the Export button at the bottom of the toolbar. In this way, the resource is ready for publication according to the linked data policies.
In the following, the functionalities of LexO will be described in detail, by means of suitable video tutorials.
Video tutorials
How to create LexO’s users. Link
This video shows the management of the users’ profiles.
How to create lexicon languages. Link
This video shows the languages creation process.
How to edit a lexical entry, referring to the OntoLex-Lemon core module. Link
This video shows the management of the core module 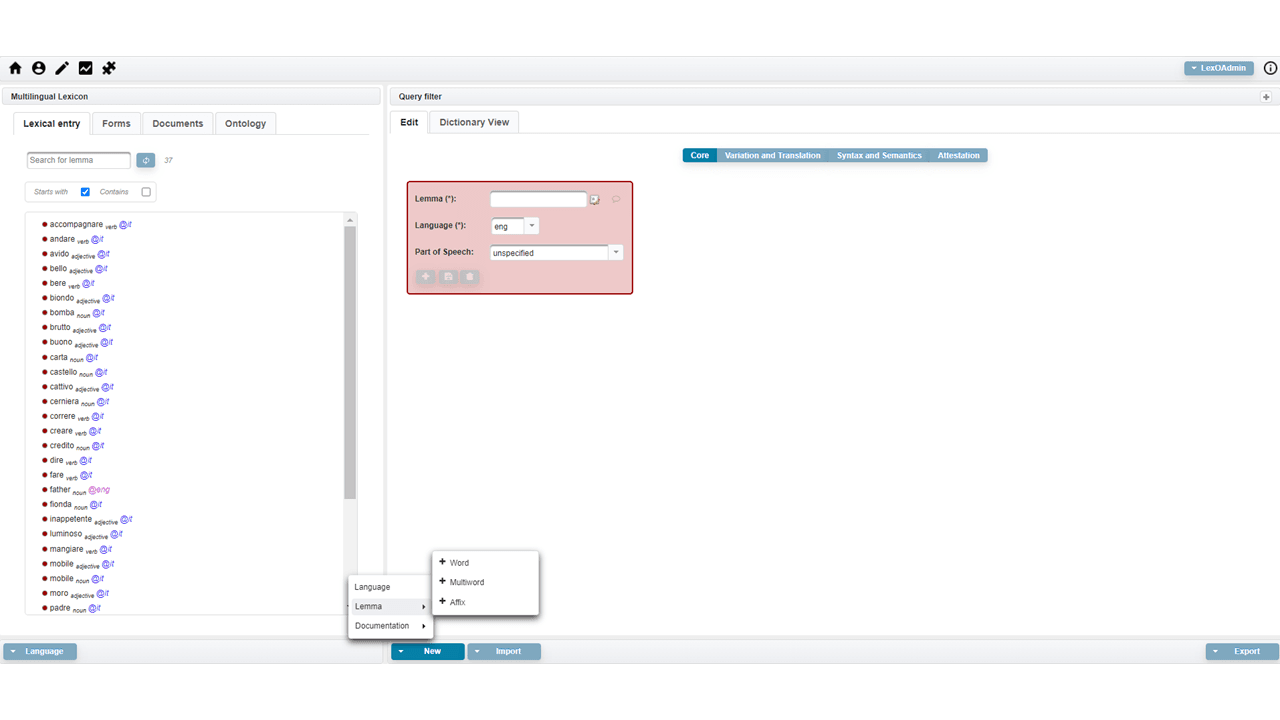
How to edit a lexical entry, referring to the OntoLex-Lemon vartrans module. Link
The following video shows the management of the variation and translation module
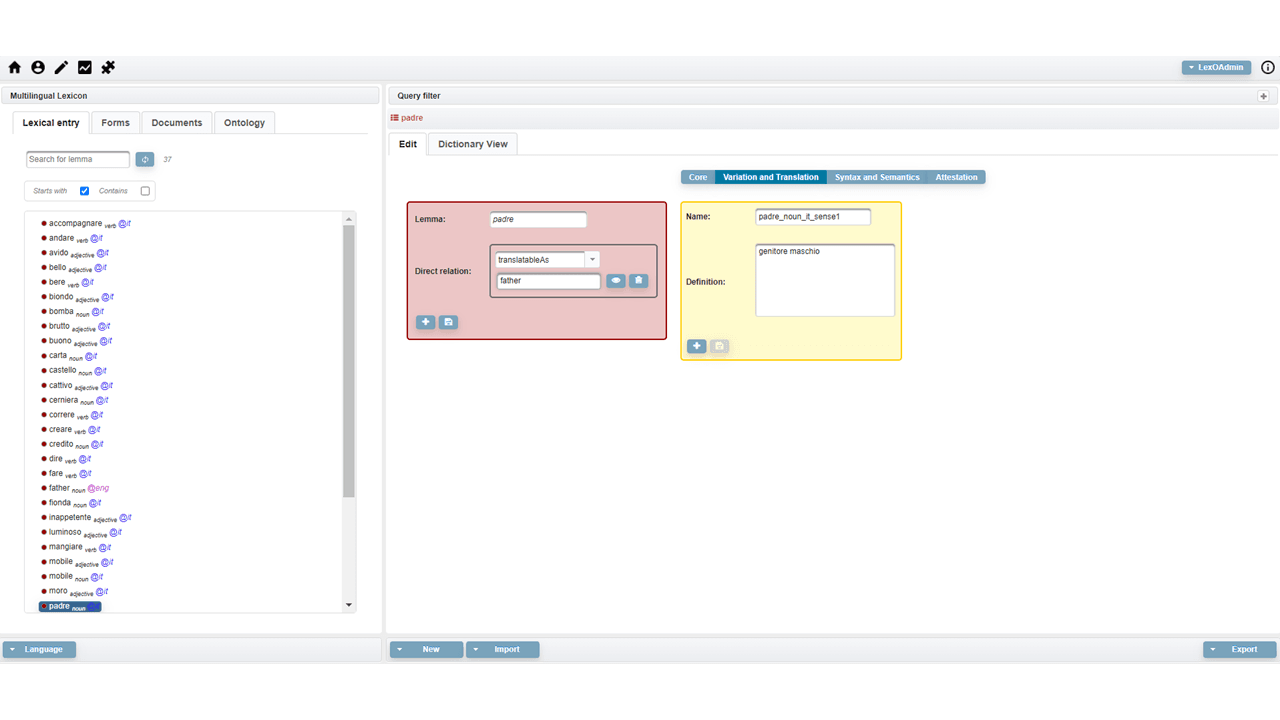
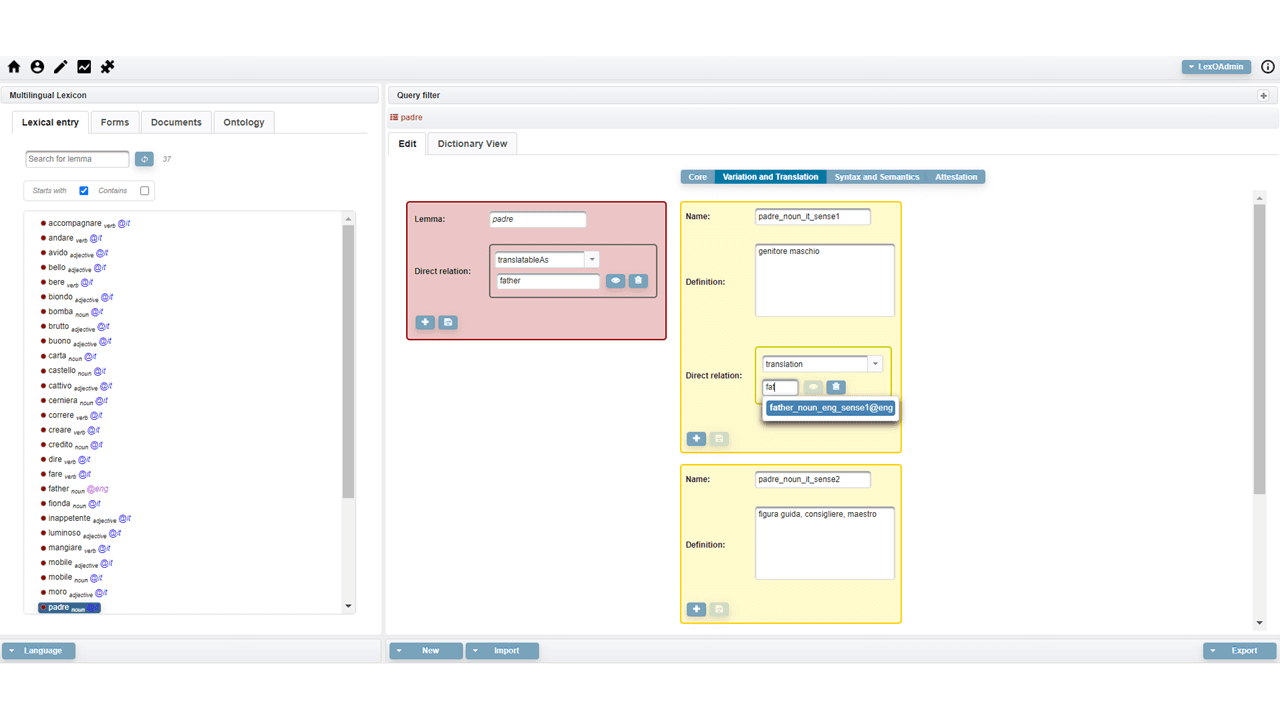
How to edit a lexical entry, referring to the OntoLex-Lemon synsem module. Link
The video shows the management of the syntax and semantics module
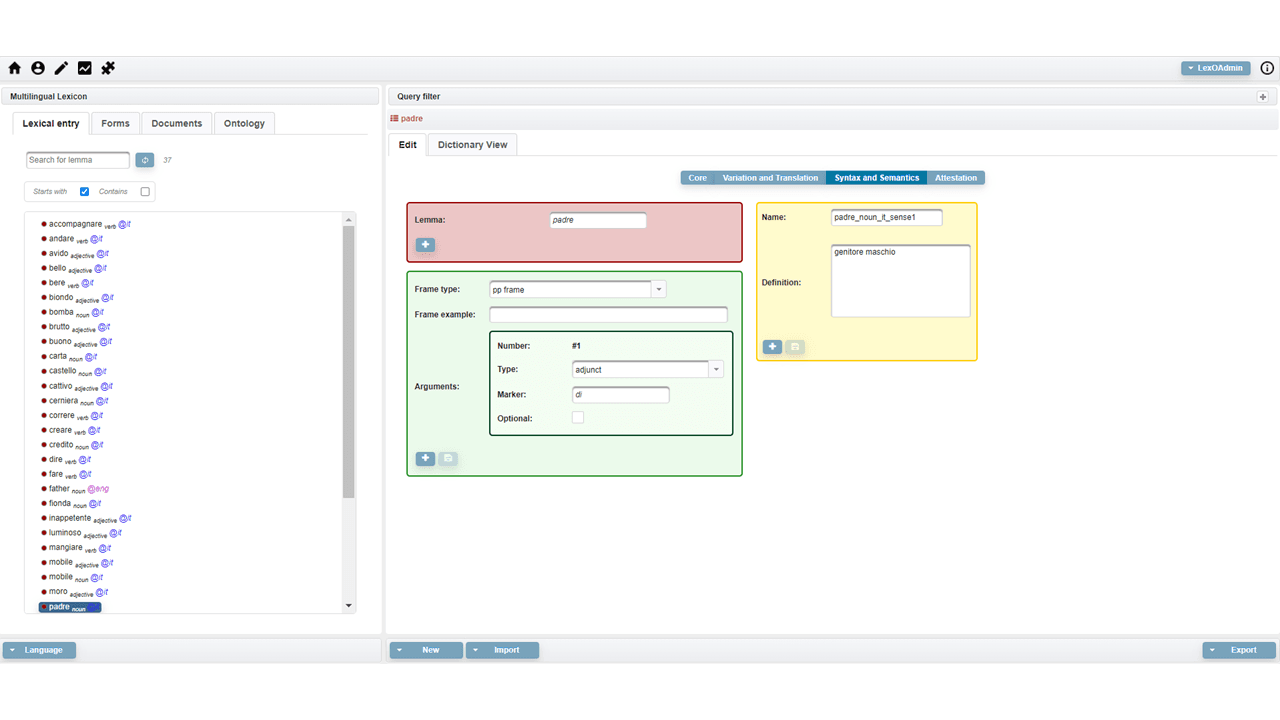
How to describe the semantics of a lexical entry. Link
The video shows how to refer a lexical entry to an external ontology
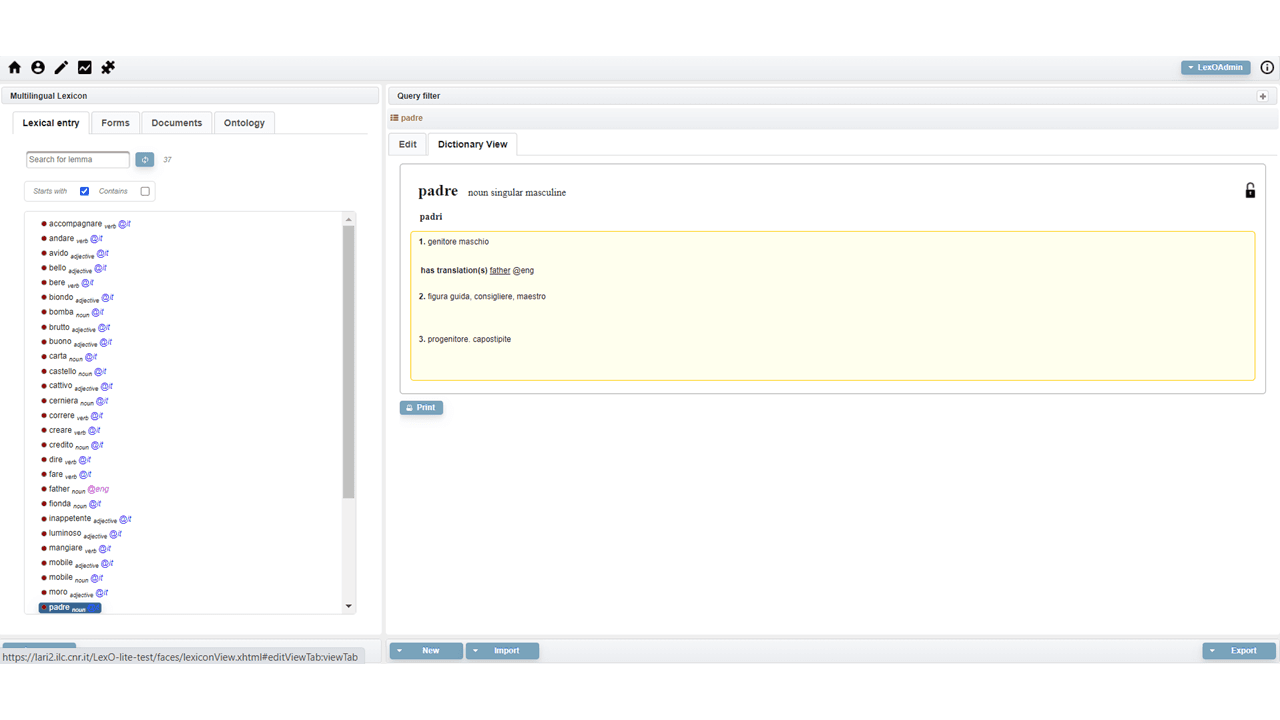
The lexical entry dictionary view. Link
The video shows the dictionary-like view of LexO
<TEI>enricher
A tool for quickly creating a dictionary in accordance with the Guidelines of the Text Encoding Initiative (TEI), ideally in the Lex-0 flavour.
See the tutorial here
References
- Andrea Bellandi (2021). LexO: An Open-source System for Managing OntoLex-Lemon Resources. Language Resources & Evaluation. https://doi.org/10.1007/s10579-021-09546-4.
- Andrea Bellandi, Emiliano Giovannetti, Simone Marchi, Silvia Piccini, Flavia Sciolette (2021). Fostering the Collaborative Creation of Linguistic Linked Open Data with LexO, an Open Source Editor of Multilingual Lexicons and Terminologies. Associazione per L’informatica Umanistica, Book of abstract. http://amsacta.unibo.it/6712/1/AIUCD2021_BOA-versione3A.pdf
- Andrea Bellandi, Monica Monachini and Fahad Khan (2019). LexO: Where Lexicography Meets the Semantic Web. Tour de CLARIN volume 2. https://www.clarin.eu/blog/clarin-it-presents-lexo-where-lexicography-meets-semantic-web
- Franciska de Jong, Bente Maegaard, Darja Fišer, Dieter Van Uytvanck & Andreas Witt (2020). Interoperability in an Infrastructure Enabling Multidisciplinary Research: The case of CLARIN. In Proceedings LREC 2020, 12th International Conference on Language Resources and Evaluation, ELRA. https://www.aclweb.org/anthology/2020.lrec-1.417/
- Monachini, Monica, e Francesca Frontini. CLARIN, l’infrastruttura europea delle risorse linguistiche per le scienze umane e sociali e il suo network italiano CLARIN-IT. IJCoL - Italian Journal of Computational Linguistics, Special Issue on NLP and Digital Humanities, 2, n. 2 (2016): 11–30. https://doi.org/10.4000/ijcol.387